
Creating a Collaborative Community for Product Managers in AI
The Vision Behind the Product Manager Collective The evolution of artificial intelligence has created a dynamic landscap...
The Vision Behind the Product Manager Collective The evolution of artificial intelligence has created a dynamic landscap...

The Vision Behind the Product Manager Club The motivation for establishing a Product Manager Club specifically tailored ...
今天最值得创业者注意的,不是又多了一个更聪明的聊天助手,而是AI 正在从「软件里回答问题」走向「在物理世界和高监管行业中直接执行」:有人用 AI-native 机器人接管工业操作,有人用物理 AI 模拟电网,有人让 AI 操作员直接进入金融合规系统干活,还有人给 AI 银行牌照、建零幻觉研究环境。一个清晰的信号是——下一波 AI 产品的护城河,不在通用能力,而在能否进入此前软件进不去的物理、合规与金融执行层。

🔗 链接:官网 | Tech.eu 报道
融资信息:完成 8500 万美元 Series A,由 CRV 领投,Samsung、LVMH、Cathay Innovation、20VC、Henkel Ventures、Inditex 参投。据称是欧洲最大机器人 A 轮。
做什么的:打造 AI-native 通用机器人,能在工业环境中实时适应变化——物流、零售、食品饮料和垃圾管理场景,直接解决劳动力短缺。
为什么值得关注: - 它不是「给机械臂加 AI」,而是定义了一个新品类:AI-native generalist robot,与传统刚性、单任务的工业机器人形成代际差异。 - 投资方阵容(Samsung + LVMH + Inditex + Henkel)横跨电子、奢侈品、快消、日化,说明工业界对「柔性机器人」的需求已经从概念变成采购预算。 - 对创业者的启发是:Physical AI 正在从「实验室演示」走向「工业部署」,而切入点不是做更强的模型,而是先找到愿意为替代人工付费的工业场景。
类比参考:「工业版 Figure AI / 通用机器人版 Tesla Optimus,但更偏商用部署」
🔗 链接:官网 | VentureBeat 报道
融资信息:完成 2800 万美元 Series A,由 Energy Impact Partners 领投,NVIDIA NVentures、Edison International、GE Vernova、Powerhouse Ventures 参投。
做什么的:用 physics-informed AI 模拟电网行为,把传统上需要数周到数月的电力工程研究压缩到实时计算,帮助公用事业应对数据中心、电动车充电等新增负载对电网的冲击。
为什么值得关注: - AI 行业整天在谈算力、模型和 agent,但真正的物理瓶颈是电网——美国电力需求预计到 2030 年增长 25%,数据中心是主要推手。 - ThinkLabs 不做 LLM,而是做 physical infrastructure AI,这是一种完全不同的技术路线和商业模式:卖给公用事业公司,而不是科技企业。 - 对创业者的启发是:AI 的下一个巨大市场,可能不在软件层,而在给 AI 自己提供基础设施的物理层——谁能帮电网更快接入数据中心,谁就在为 AI 行业的扩张铺路。
类比参考:「电网版 Ansys / AI 时代的电力基础设施仿真平台」
融资信息:完成 1.25 亿美元合并种子轮 + A 轮,成立仅一年。投资方详情参见 WSJ 原文。
做什么的:AI 驱动的网络安全初创公司,目标是用 AI 重做企业安全运营——从威胁检测到响应自动化。
为什么值得关注: - 一年内拿到 1.25 亿美元种子+A 轮,说明安全赛道对 AI 的资本投入已经进入「抢座位」阶段。 - 网络安全是「高信任、高粘性、高续费」的品类,一旦 AI 安全产品证明效果,客户替换意愿极低,容易形成长期 ARPU。 - 对创业者的启发是:AI 安全不是一个细分赛道,而是一个正在被 AI 重写的基础设施层,从 SOC 自动化到 AI agent 安全治理,空间巨大。
类比参考:「AI 原生版 CrowdStrike / Wiz,但更偏向自动化响应」
融资信息:获 Y Combinator 支持(Spring 2026),独立融资金额未披露。
做什么的:专为金融服务设计的 AI Operator,通过观察企业 SOP 和员工操作来学习如何导航内部系统,自动化处理账户解冻、AML/KYC 检查、还款调整等复杂合规流程,号称可自动化 96% 的任务。
为什么值得关注: - 它不靠 API 集成,而是靠「观察人来学习」——这与 Eloquent AI 之前 Walter 的思路如出一辙,但切入点是金融合规。 - 官方引用「金融机构 AI 采用率不到 1%」这个数据,核心论点是:通用 AI 在金融业失败的原因是合规、幻觉和重工程需求。 - 对创业者的启发是:金融服务的 AI 市场不是「能不能做」的问题,而是「敢不敢用」的问题——产品设计的起点应该是合规、可追溯和零工程侵入,而不是功能丰富。
类比参考:「金融合规版 UiPath + AI Agent / 不写代码的金融自动化操作员」

融资信息:获 Y Combinator 支持(Spring 2026),独立融资金额未披露。
做什么的:打造美国第一家 AI-native neobank。从一个聚合所有金融产品的 AI 助手开始——连接信用卡、投资、加密货币、401k、储蓄——提供个性化建议和自动化财务 agent,最终目标是推出 AI 原生的银行产品。
为什么值得关注: - 它不是给传统银行加一个聊天机器人,而是从零设计一家以 AI 为核心引擎的银行——这是"AI-native"在金融领域最激进的产品化尝试。 - 聚合策略(先连接所有产品)→ 建议(AI 分析优化)→ 自有产品(推出 AI 定价的金融产品),这是一个非常清晰的 产品演进路径。 - 对创业者的启发是:AI 颠覆一个行业最彻底的方式,不是给现有玩家加功能,而是用 AI 重新定义这个行业的核心产品形态。
类比参考:「Monzo / Chime 的 AI-native 版本 / 如果 AI 来开一家银行」
融资信息:获 Y Combinator 支持(Spring 2026),独立融资金额未披露。
做什么的:面向高信任环境(银行、律所、合规部门)的零幻觉 AI 深度研究 agent 构建平台,连接 40+ 企业数据源(CRM、邮件、知识库),让用户搭建精确、可重复、不胡说的工作流。
为什么值得关注: - 团队来自 Deutsche Bank 和 Amazon,核心论点是:深度研究 agent 能替代大量白领工作,但部署被合规部门卡住了——因为现有 AI 会「编造」。 - 产品策略不是做更强的 LLM,而是做可控、可重复、可审计的研究工作流构建器,这更贴近企业采购逻辑。 - 对创业者的启发是:在需要高信任的场景中,「不犯错」比「更聪明」更有商业价值。零幻觉不是技术问题,而是产品定位问题。
类比参考:「企业合规版 GPT Researcher / 可审计的 AI 研究工作流平台」
融资信息:获 Y Combinator 支持(Spring 2026),独立融资金额未披露。
做什么的:用 Vision Language Model 实时观看每一个用户会话,自动检测产品中的体验问题——静默流失、UI 困惑、错误阻塞——然后自动生成诊断摘要、会话片段和 Linear 工单或 PR 草稿。
为什么值得关注: - 传统产品分析告诉你「用户点了什么」,Decipher 告诉你「用户为什么困惑、在哪里卡住、该怎么修」——这是从 analytics 到 autonomous insight 的跳跃。 - 官方比喻是「1000 个 QA 实习生在实时看每一个用户会话」,这种 product-led 的 AI 产品的想象力在于把被动分析变成主动发现+自动修复。 - 对创业者的启发是:Vision Language Model 不只是用来看图说话,还可以用来看用户怎么使用你的产品,然后把洞察直接变成行动。
类比参考:「FullStory / Hotjar 的 AI Agent 版 / 自动化产品体验监控层」
🔗 链接:官网 | Show HN 讨论
融资信息:Show HN 新项目,融资信息未披露。
做什么的:为 coding agent 部署隔离的 Linux 虚拟机,每个 agent 独占一个完整环境——文件系统、后台进程、网络全权控制——通过 JSON 模板初始化,支持自托管在 KVM 支持的 Linux 系统上。
为什么值得关注: - 当团队开始同时跑多个 coding agent(Claude Code、Cursor、Devin 等),agent 之间的运行环境冲突正在成为新瓶颈。 - Bastion 的产品观点非常简洁:给每个 agent 一台虚拟电脑,就像给每个员工一台笔记本电脑一样自然。 - 对创业者的启发是:coding agent 的基础设施层正在快速分化——runtime 环境、验证环境、编排环境——每一个方向都可能长出独立产品。
类比参考:「Coding Agent 版 Docker / 给 AI agent 用的虚拟桌面基础设施」
AI 正在从软件进入物理世界:Theker(机器人)和 ThinkLabs(电网仿真)代表了一个清晰方向——AI 的下一个增长空间不只是软件市场,而是之前软件进不去的物理基础设施。
高监管行业的 AI 操作员崛起:Eloquent AI(金融)、Clarm(合规研究)、Selfin(银行)说明——通用 AI 在金融场景的失败率,正在催生一批专门为高监管行业设计的 AI 操作层。
Agent 基础设施继续分化:Bastion 给每个 agent 分配独立 VM,Decipher 用 VLM 监控用户体验——agent 时代的「操作系统」和「可观测性」层正在同步成型。
今天最值得创业者注意的,不是又多了一个更强的通用模型,而是一批新产品开始绕过“重做软件界面”这条老路,直接进入旧系统、旧流程和旧设备内部干活:有人让 AI 登录 SAP 和 Oracle 处理制造后台,有人让 AI 直接调度实验室仪器,有人把工业分销、客户运营、医疗影像治理、组织流程梳理都做成可执行层。一个越来越清晰的信号是,下一波 AI 产品的价值,不只是“会回答”,而是能否真正接管老系统之上的操作工作。
融资信息:公司披露已在正式启动融资前拿到 70 万美元,并已排上 80+ 个 VC 沟通;同时已有 5 家企业设计合作客户、150+ inbound demo。
做什么的:用 AI agents 持续采访企业员工,自动抽取流程、决策规则、工具链和交接关系,生成可供企业自动化和 agent 使用的“活的组织上下文层”。
为什么值得关注: - 它切的不是“再给员工一个聊天框”,而是 AI 转型前最贵、最慢的 discovery 阶段。 - 传统流程梳理往往要咨询公司做数月访谈,Ontora 把这一步压缩到几天,且上下文会持续更新,不会很快过时。 - 对创业者的启发是:企业 AI 项目很多不是输在模型,而是输在 没人先把真实业务怎么运转搞清楚。
类比参考:“企业流程访谈版 Palantir / AI 转型版组织 discovery layer”
融资信息:获 Y Combinator 支持(Spring 2026),公开页面未披露独立融资金额。
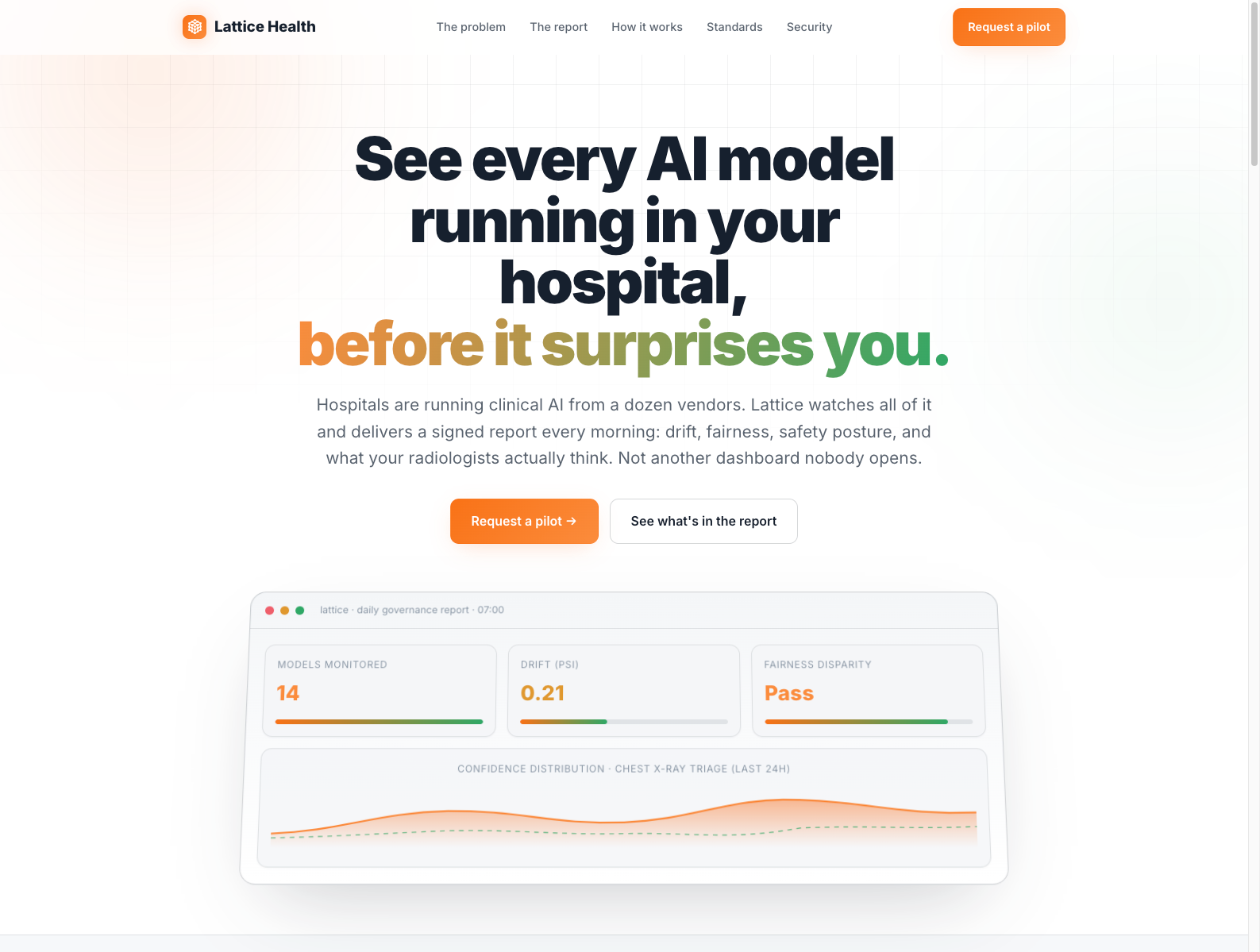
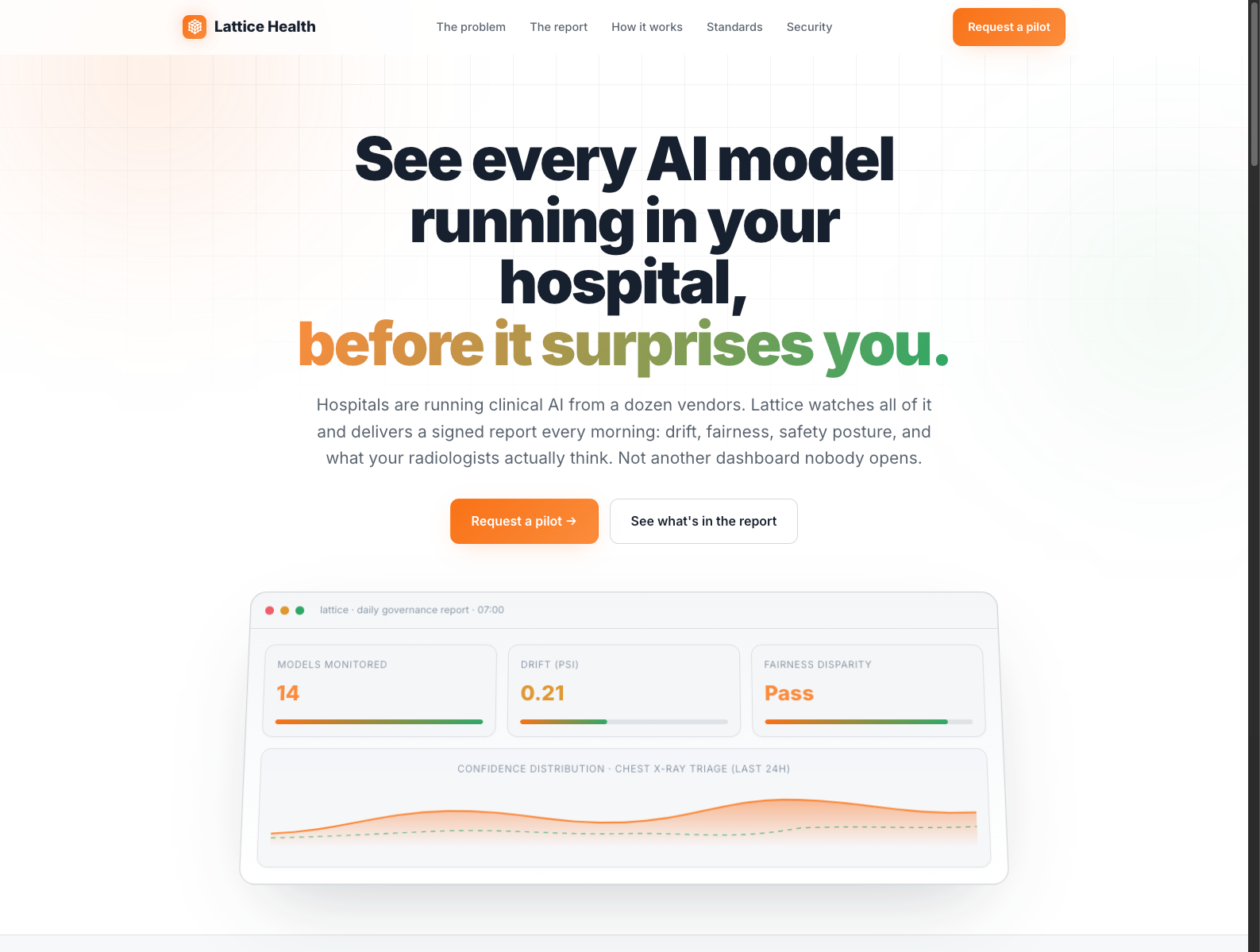
做什么的:为医院已部署的医疗影像 AI 提供持续监控与治理层,追踪模型是否 drift、与放射科医生结论的一致性,以及不同患者亚群上的表现差异。
为什么值得关注: - 医疗 AI 真正难的不是模型上线,而是 上线后还能不能持续安全、合规地工作。 - Lattice 采用只读接入,不直接影响临床决策,把自己定位成“监控与证据层”,更符合医院采购逻辑。 - 对创业者的启发是:高监管行业里的 AI 新机会,往往来自 post-deployment governance,而不是前端体验升级。
类比参考:“医疗影像 AI 版 Datadog / Arize + 合规治理层”
融资信息:获 Y Combinator 支持(Spring 2026),未见独立融资金额披露。
做什么的:把 Slack、邮件、会议、Discord、通话中的客户承诺、bug、需求、阻塞和扩容信号自动汇总,并推动后续动作落地,比如建工单、发更新、做挽留、触发扩容流程。
为什么值得关注: - 很多创业团队输给对手,不是产品差,而是 承诺没人跟、问题没人收口、客户信号分散在各处。 - Akkari 切的是从首个销售电话到续费扩容的“customer ops 执行层”,比单点客服 bot 更接近收入结果。 - 对创业者的启发是:AI 在 B2B 里最容易形成价值的地方,常常不是回答问题,而是 替团队把 follow-through 做完。
类比参考:“客户成功版 Linear + RevOps agent”

融资信息:获 Y Combinator 支持(Spring 2026),公开页面未披露独立融资金额。
做什么的:为工业分销商和制造商自动处理 sourcing、报价、订单录入、采购与对账,把原本在邮件、PDF、Excel、传真和 ERP 之间来回切换的流程做成 agent 工作流。
为什么值得关注: - 这是非常典型的“老行业、高频、强 ROI、系统老旧”的切口,客户损失直接体现在 报价慢导致丢单。 - Hexa 不要求客户替换 ERP,而是直接嵌进现有系统里,把 reps 从键盘搬运工变成审核者。 - 对创业者的启发是:很多垂直 AI 的最佳 GTM,不是替换旧系统,而是 先贴着旧系统把最重的人工作业接管掉。
类比参考:“工业分销版 ServiceNow + ERP 内嵌 agent”
融资信息:获 Y Combinator 支持(Spring 2026),公开页面未披露独立融资金额。
做什么的:Walter 不是新建一套系统,而是直接给 AI 一个登录账号,让它像新员工一样进入 SAP、Microsoft Dynamics、Oracle、Teams、Outlook 等现有软件,自动处理 PO 录入、供应商下单、价格错误检查等制造后台任务。
为什么值得关注: - 它最强的产品观点是:别再做集成了,直接让 AI 去操作现有软件。 - 这大幅降低企业替换系统的阻力,也说明 agent-native 产品开始从 API-first 走向 UI / workflow-first automation。 - 对创业者的启发是:很多传统行业的软件真正问题不是功能缺失,而是 仍然需要大量人坐在系统前重复点击。
类比参考:“制造业版 AI 员工 / 给 SAP 和 Oracle 的操作员 Agent”
融资信息:获 Y Combinator 支持(Spring 2026),公开页面未披露独立融资金额。
做什么的:研究人员用自然语言描述实验后,Infera 会把它转成可执行、可校验的 instrument-ready run,涵盖 protocol logic、仪器脚本、数据回传、分析与库存检查。
为什么值得关注: - 它切中的不是“科学家写报告”这种浅层场景,而是 实验仪器之间长期无法真正协作 的系统性问题。 - Infera 把 SOP、仪器约束、库存状态、历史实验经验放进同一个上下文层,显著提高实验自动化可信度。 - 对创业者的启发是:在垂直高专业场景,AI 价值不在更会聊天,而在 把意图翻译成真实世界里的可执行动作。
类比参考:“实验室版 Claude Code / 科学仪器操作系统”
融资信息:获 Y Combinator 支持(Spring 2026),公开页面未披露独立融资金额。
做什么的:Zenbu 想做“管理 coding agents 的 IDE”,把多 agent 并行、结果审查、上下文切换、验证和插件扩展做成一套可定制界面。
为什么值得关注: - 当团队开始同时跑多个 coding agents 后,新的问题已经不再是“能不能生成代码”,而是 怎么管理 agent 之间的复杂度。 - Zenbu 选择插件化路线,而不是强推单一工作流,说明“agent IDE”可能会像早年的开发环境一样,形成新的生态层。 - 对创业者的启发是:coding agent 赛道的下一步,不只是更强模型,而是 围绕 agent 协作、审查和编排长出新的工作台。
类比参考:“Cursor / VS Code 的多 coding-agent orchestration 版本”
今天最值得创业者注意的,不是又有哪个模型 benchmark 更高,而是一批新公司开始集中补上“Agent 真正进生产”之前最缺的那层基础设施:有人给 coding agent 提供完整验证环境,有人让 agent 能持续学习且不遗忘,有人重做 agent-first commerce,有人把企业 GenAI 采用和 ROI 量化做成单独产品层。一个越来越清晰的信号是,下一波 AI 创业不只是在做更会说的 Agent,而是在争夺 验证、采用、合规、运营、交易 这些离收入更近的生产化中间层。
融资信息:官网宣布产品 GA,并同步披露完成 700 万美元 Seed,由 Greylock 领投。
做什么的:Niteshift 想做的是 coding agents 的 full-stack cloud——不是只给 Agent 一个 repo,而是把数据库、Docker 服务、浏览器验证、日志、CI 和可并行运行环境一起搬到云端,让代码 Agent 能自己完成“写完—验证—继续改”的闭环。
为什么值得关注: - 现在很多代码 Agent 卡住的地方,不是不会写,而是没法在真实运行环境里自证它写得对。 - Niteshift 把“验证环境”单独产品化,说明 coding agent 的下一层竞争,已经从模型能力转向 环境供给与并行执行能力。 - 对创业者的启发是:如果你做 Agent 基础设施,真正能形成壁垒的往往不是 prompt,而是 让 Agent 独立交付结果的 runtime。
类比参考:“给 Claude Code / Devin / Cursor Agent 用的云开发与验证底座”
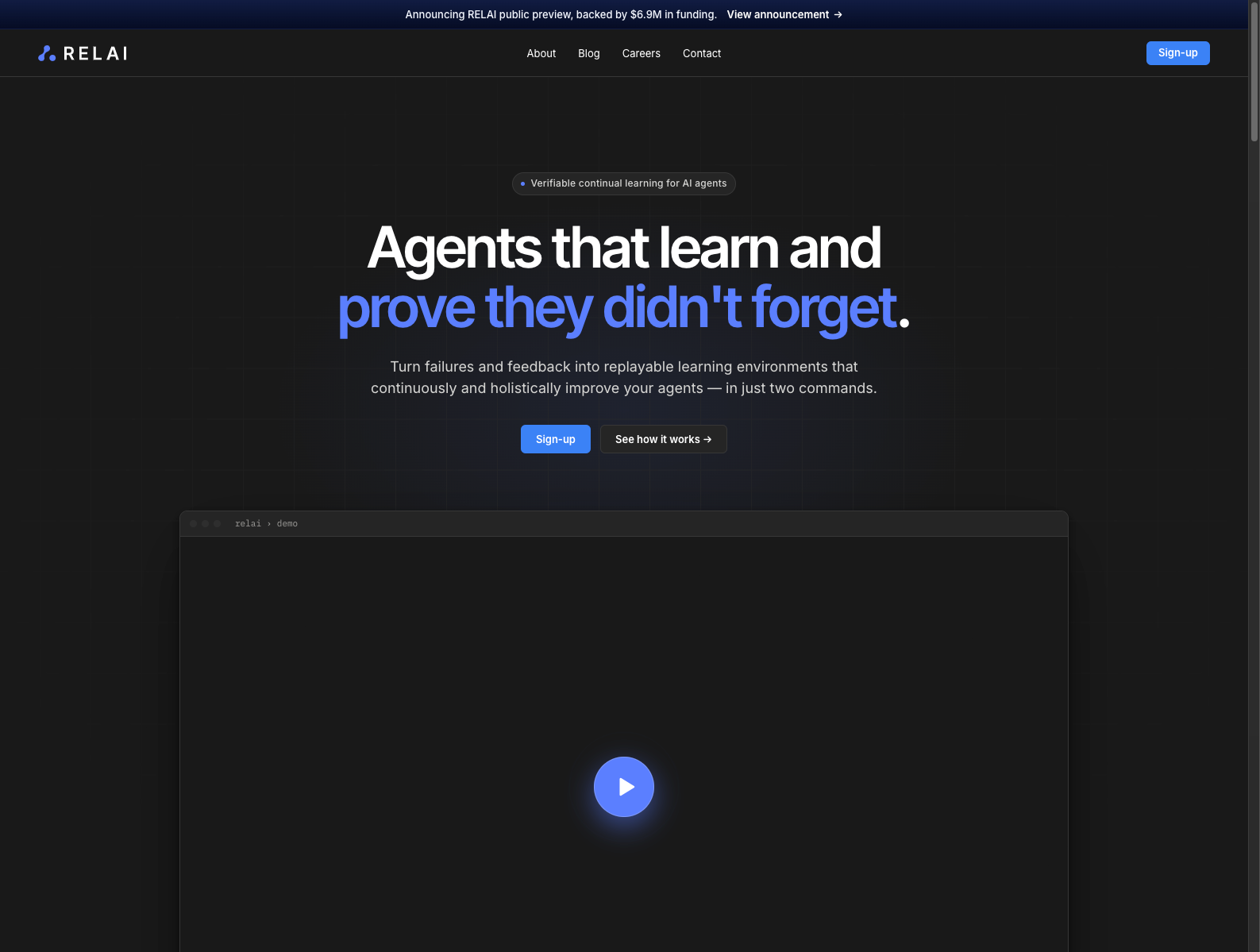
融资信息:官方博客披露,RELAI 获得 690 万美元融资,并已开放 limited-access onboarding。
做什么的:RELAI 做的是 agent 的 continual learning engine。它把失败案例、trace、tool call、memory 和人工反馈重建成 replayable learning environments,再自动搜索可以改进 agent 的 prompt、tool、workflow、memory 或 code 层修复方案,并在回归集上验证“不遗忘”。
为什么值得关注: - 现在企业 Agent 最大的问题之一不是首次上线,而是上线后怎么持续变好且不把旧能力修坏。 - RELAI 没把问题定义成“做更强 eval”,而是定义成 failure → learning environment → validated improvement 的持续系统。 - 对创业者的启发是:Agent 时代一个重要新层,不是再做一个 assistant,而是做 agent 的学习系统和变更控制层。
类比参考:“Agent 版 CI/CD + regression learning engine”
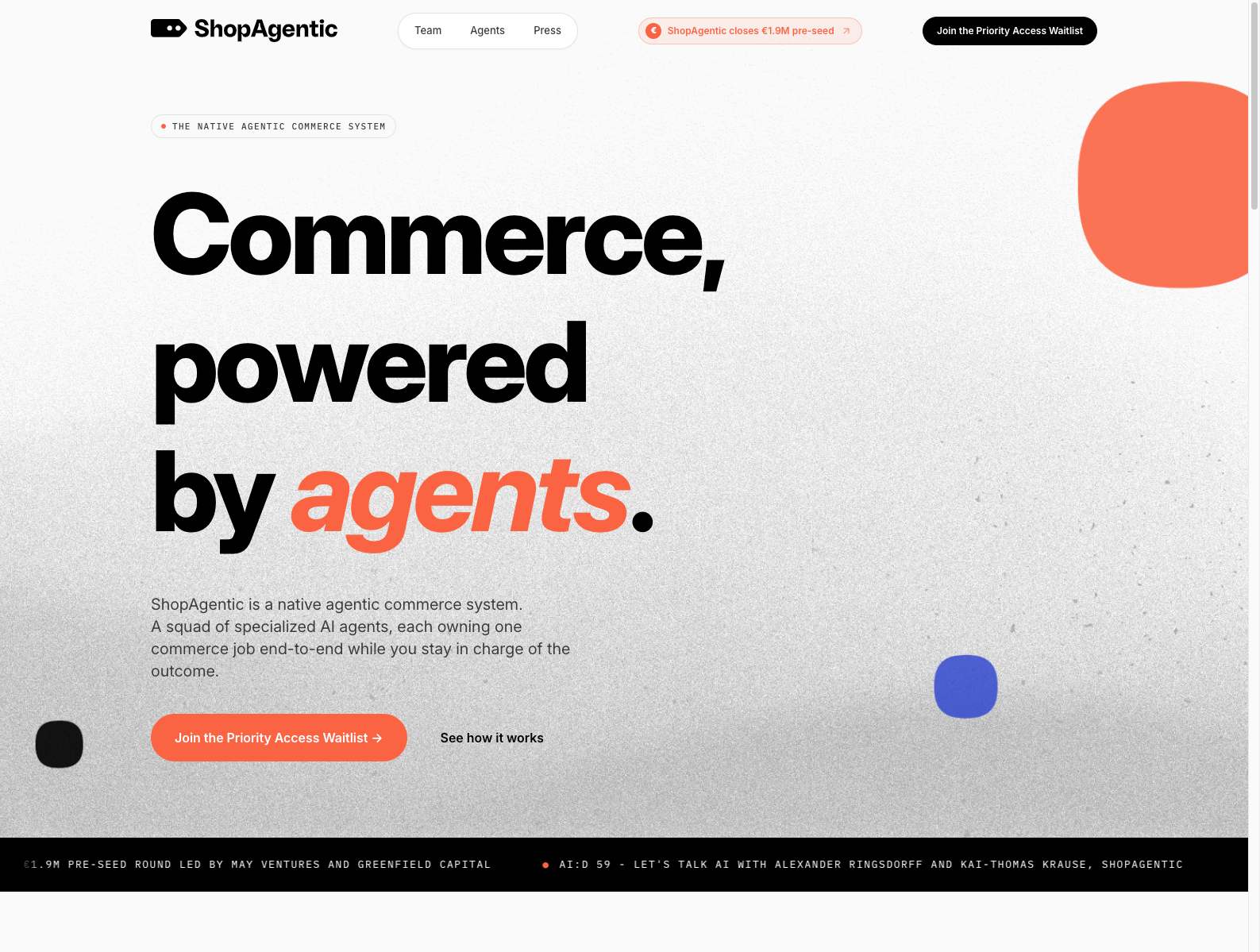
🔗 链接:官网 | Pre-seed 公告
融资信息:公司于 6 月 11 日宣布完成 190 万欧元 oversubscribed pre-seed,由 May Ventures 和 Greenfield Capital 领投。
做什么的:ShopAgentic 在赌一个很大的变化:未来不是人逛店,而是 AI assistant 代表人完成搜索、比较、谈价和下单。它想提供“agentic commerce system”,让品牌和零售商在商品结构化数据、库存、价格、交易接口和 agent-first storefront 上都能直接服务 AI 买手。
为什么值得关注: - 很多电商公司还在想怎么给商城加 AI,ShopAgentic 直接换了问题:如果消费者入口变成 agent,商家该怎么重建基础设施? - 它把“agent readiness”从营销概念变成系统工程,这对零售 SaaS、支付、搜索、导购都是新机会。 - 对创业者的启发是:AI 不只是提升转化率,也可能重写谁在做购买决策、谁在触发交易。
类比参考:“Shopify / Salesforce Commerce Cloud 的 agent-first 重做版”

🔗 链接:官网 | Tech.eu 报道
融资信息:公开报道显示,Mendo 完成 1200 万欧元 Series A,由 Ventech 和 Educapital 领投,Tomcat 与 OVNI Capital 参投。
做什么的:Mendo 不再做一个独立 AI 工具,而是把自己定位成 The GenAI adoption & analytics platform for large enterprises。它嵌进企业现有 Copilot、内部 GPT 和 agent 工具里,帮助企业看清谁在用、怎么用、ROI 如何、哪些团队适合推 agent。
为什么值得关注: - 过去大家默认“买了 Copilot 就会自然发生 adoption”,Mendo 证明 采用率、训练、最佳实践和 ROI 可视化 本身就是独立产品机会。 - 它切的不是模型层,而是企业 GenAI rollout 的 adoption layer,这比再做一个聊天入口更贴近真实预算。 - 对创业者的启发是:企业 AI 市场正在分层,除了模型、应用、Agent,还会长出一层专门负责 采用、治理与价值量化 的中间件。
类比参考:“企业 Copilot/Agent 的 adoption OS + analytics layer”
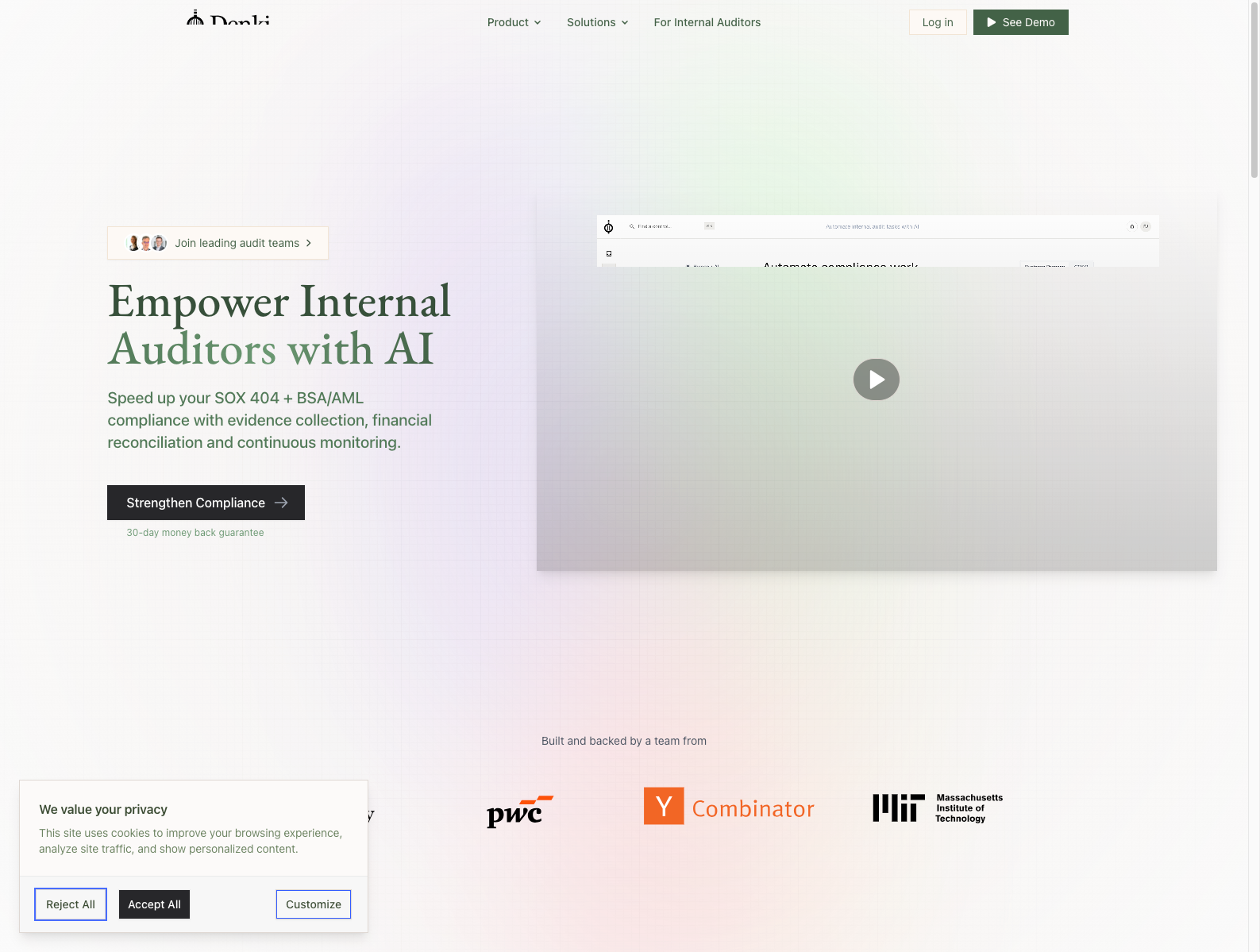
融资信息:公开报道显示,Denki 获得约 410 万美元早期融资;YC 页面当前重点披露的是其 internal audit 自动化产品与客户切入方式。
做什么的:Denki 把自己写成 full-stack AI financial audit firm。它不是做单点审计助手,而是直接自动化 control mapping、walkthrough interviews、testing 和 working papers 产出,并强调完整 audit trace。
为什么值得关注: - 审计是典型“必须做、很贵、极缺人、结果要可追责”的流程,天然适合 AI 先从执行层切入。 - Denki 最有意思的不是“会写工作底稿”,而是把传统审计公司的一部分交付链条产品化。 - 对创业者的启发是:高价值专业服务行业里,最值得做的 AI 往往不是 copilot,而是 software-enabled service / AI-native firm。
类比参考:“内部审计版 AI 事务所 / AuditBoard + AI delivery engine”
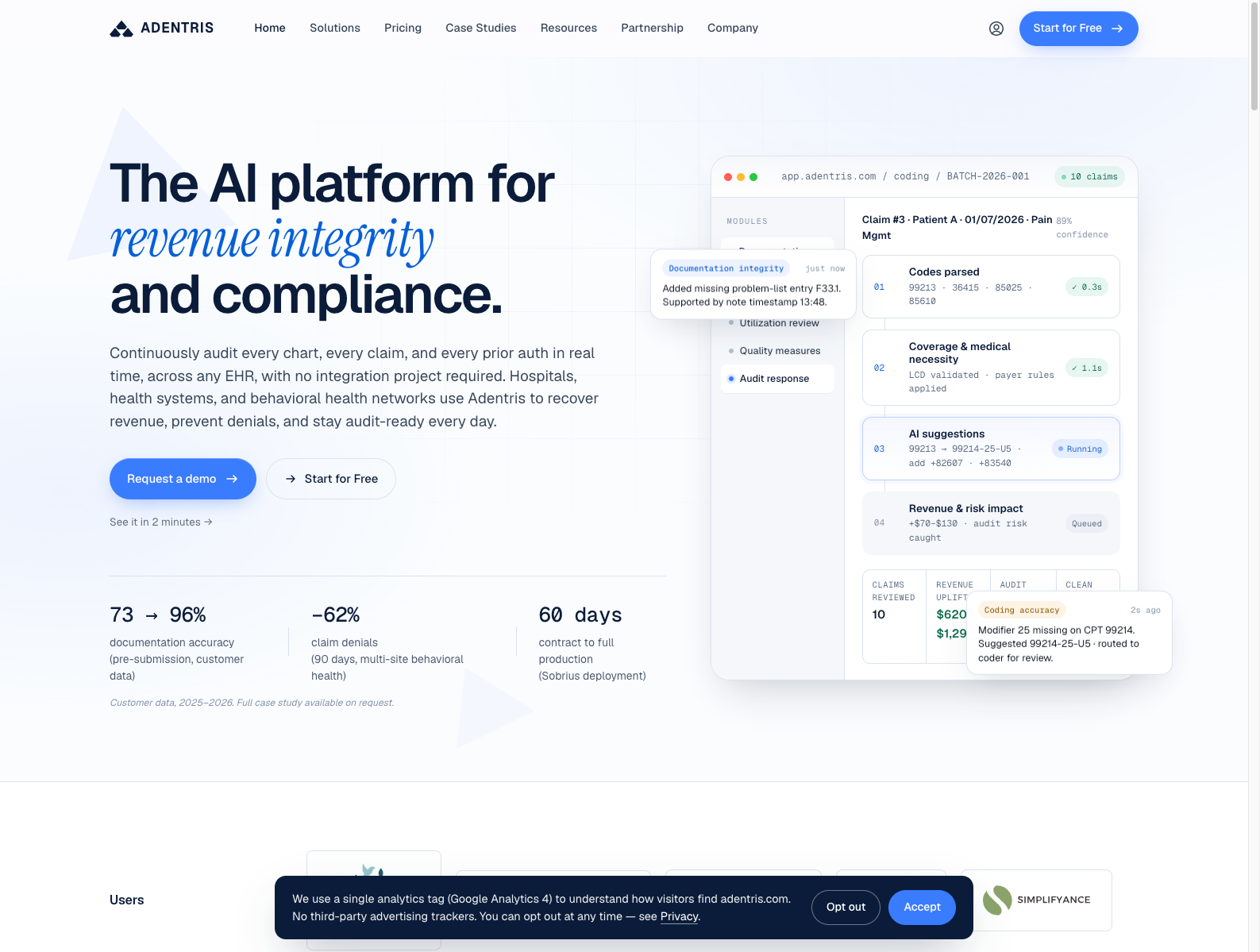
融资信息:获 Y Combinator 支持;YC 页面披露,公司在本届 YC 期间已做到 5.4 万美元 ARR,并在多家医院和诊所推进 commercial pilots。
做什么的:Adentris 做的是 医疗文档实时合规 autopilot。它直接连进医院 EHR,实时监控临床记录和 staff activity logs,用 AI agents 在错误变成 claim denial、audit 或罚款之前,先发现并推动责任人修正。
为什么值得关注: - 医疗 AI 里很多人盯着诊断和 scribe,Adentris 切的是更贴近财务后果的 documentation compliance。 - 它的关键不只是提醒,而是发起快速纠错对话,说明 AI 在医院里开始从“建议者”变成 流程纠偏者。 - 对创业者的启发是:真正容易拿到预算的 AI,常常不是改善体验,而是先减少收入损失、审计风险和合规摩擦。
类比参考:“医院 EHR 上的一层实时合规风控 Agent”
今天最值得创业者注意的,不是又多了一个更强的模型,而是越来越多 AI 公司开始直接售卖“结果交付”而不是“工具席位”:有人把企业上下文做成 agent 可用的图谱层,有人把法务、私募尽调、电话客服、FDA 申报、州牌照管理这些高责任流程整包接手。一个越来越清晰的信号是,下一波 AI 产品竞争,不在回答更聪明,而在谁能把专业服务流程压缩成可审计、可定价、可对结果负责的交付单元。
🔗 链接:官网
融资信息:公开报道显示,获 2400 万美元 Series A 融资,用于把企业内部碎片化业务语境组织成可供 AI 使用的 context graph。
做什么的:Jedify 不是再做一个企业聊天入口,而是把表、指标、业务定义、团队知识和系统关系串成一层 enterprise context graph,让 AI agents 和分析团队在同一套业务语义上工作。
为什么值得关注: - 很多企业 AI 项目不是输在模型,而是输在“上下文不统一”,不同 agent 读到的是彼此冲突的数据解释。 - Jedify 把“业务语义层”单独产品化,这说明 AI 时代的数据基础设施正在从仓库层往 context 层上移。 - 对创业者的启发是:如果你服务复杂企业场景,真正值钱的未必是最后那句回答,而是让所有自动化都基于同一套可信业务上下文。
类比参考:“企业数据仓库之上的 AI context fabric / 语义图谱层”
🔗 链接:官网
融资信息:公开报道显示,Sandstone 完成 3000 万美元融资,主打面向企业法务团队的 in-house legal AI 平台。
做什么的:它把 legal intake、文档关系、上下文检索、任务路由、红线审阅、指标分析放进同一套系统,让法务部门不再只是一堆文档和请求箱,而是一套可操作的 Legal Relationship Management 平台。
为什么值得关注: - 法务是典型高责任知识工作,客户买的不是“会写”,而是 更少漏单、更快周转、更可追溯。 - Sandstone 的切法不是给律师一个 copilot,而是重做法务部门的工作底座,这比单点提效工具更容易沉淀长期数据与流程优势。 - 对创业者的启发是:在高责任场景,AI 最强的产品形态常常不是助手,而是 带工作流、权限、上下文和指标体系的系统层产品。
类比参考:“企业法务版 ServiceNow + Harvey”
🔗 链接:官网
融资信息:官网披露,Capsa AI 刚完成 1800 万美元 Series A。
做什么的:Capsa AI 是面向 private equity、private credit、infrastructure 等私募资本场景的 AI Operating System,连接 CRM、共享盘、第三方数据库和历史 deal folder,帮助投资团队加快研究、评估、投委会准备和知识复用。
为什么值得关注: - 它切中的是一个“单客价值高、历史数据重、决策链长”的行业,天然适合做高 ARPU 的垂直 AI。 - 官方文案强调 full traceability、single-tenant / VPC / on-prem,这说明 金融机构买 AI,第一诉求仍然是可控与可信。 - 对创业者的启发是:不要只做通用研究助手,真正高价值的 AI OS 往往来自对一类专业决策流程的深度重构。
类比参考:“私募投资团队版 Bloomberg Terminal + AI deal team”
🔗 链接:官网
融资信息:公开报道显示,fonio.ai 获得 1700 万美元 seed 融资。
做什么的:fonio 用 AI 电话助手切入企业来电场景,支持欢迎语、通话处理逻辑、通话后转写和回调/转接,核心卖点是“几分钟上线”的电话自动化,以及 数据留在欧洲 的本地合规叙事。
为什么值得关注: - Voice AI 已经不只是北美客服替代,fonio 证明 欧洲本地化、合规优先 也能成为产品差异点。 - 官网直接强调自研 orchestration layer,而不是白标美国服务,这是一种很清晰的 GTM:把“技术主权 + 数据主权”卖给企业客户。 - 对创业者的启发是:同样做 AI 电话,不同市场真正的决胜点可能不是模型音色,而是部署速度、监管边界和数据归属。
类比参考:“欧洲合规版 Aircall + AI phone agent”
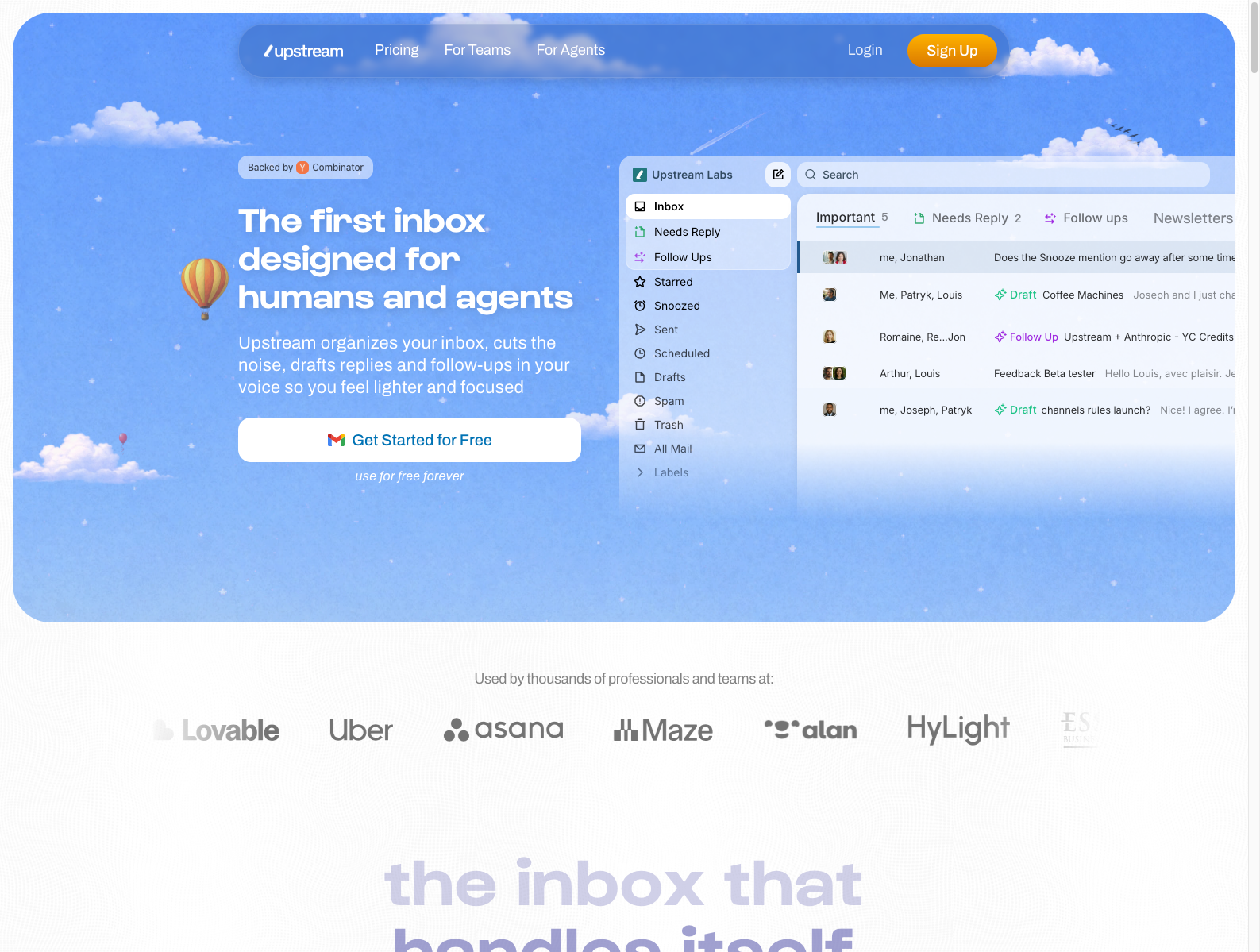
🔗 链接:官网
融资信息:公开报道显示,Upstream 完成 300 万美元 pre-seed,并宣布产品进入 GA。
做什么的:Upstream 试图重做邮件收件箱本身:AI 自动识别哪些邮件需要回复、哪些该跟进、哪些可以忽略,并按你的写作风格提前生成草稿和 follow-up,把 inbox 变成一个 人类与 agent 共用的工作台。
为什么值得关注: - 过去几年很多创业公司想“替代邮箱”,但 Upstream 的聪明点在于它不是离开 email,而是把 email 直接改造成 agent-native 入口。 - 官网呈现方式非常产品化:不是抽象讲 agent,而是把 Needs Reply、Follow Ups、Drafts 这些结果直接可视化。 - 对创业者的启发是:AI 产品想切个人效率工具,最好的路径不一定是新建入口,而是 接管用户已经高频打开的旧入口。
类比参考:“Superhuman / Gmail 的 agent-native 版本”
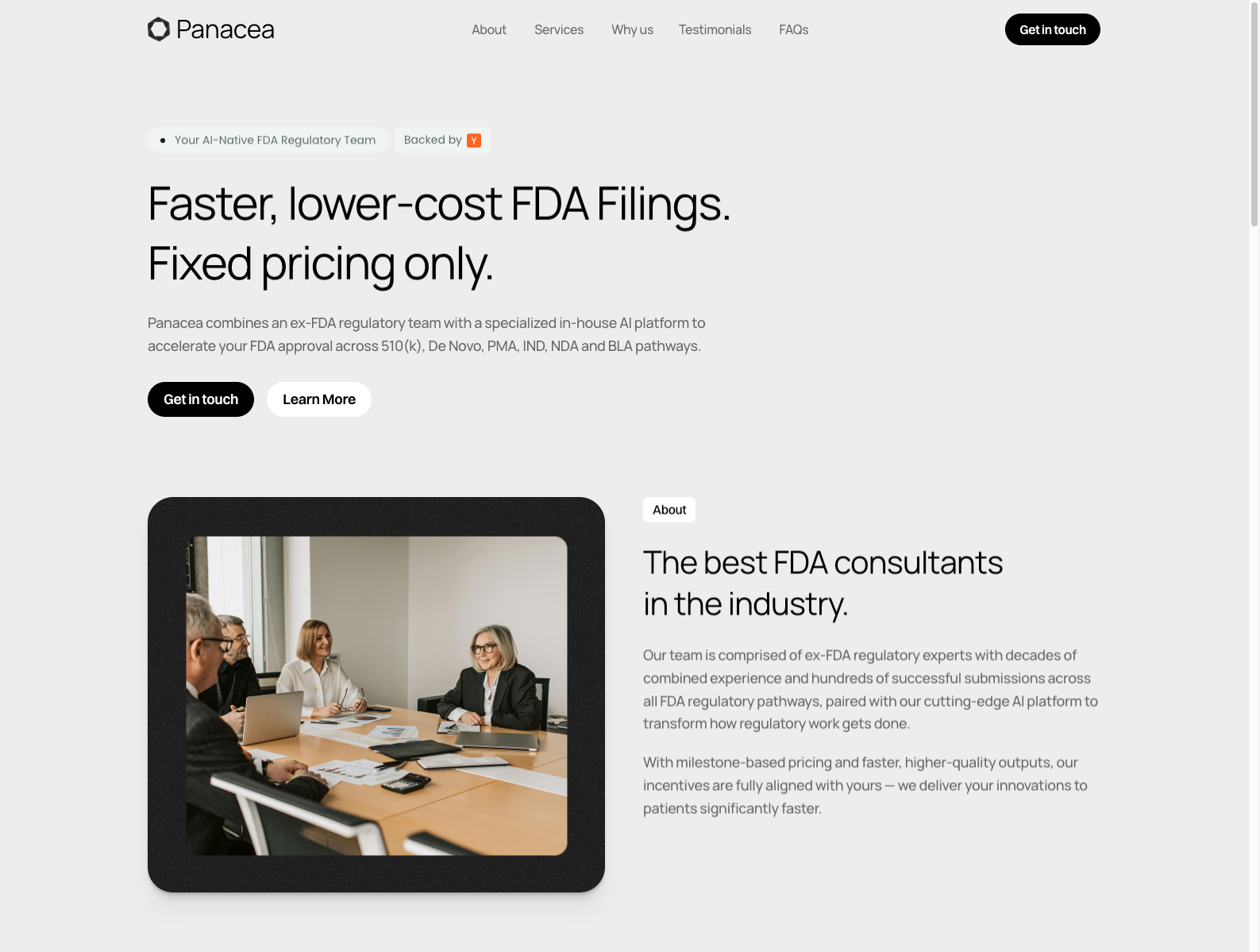
融资信息:获 Y Combinator 支持;独立融资金额暂未见公开披露。官网主打 fixed, milestone-based pricing。
做什么的:Panacea 把 ex-FDA regulatory experts 和自研 AI 平台绑定在一起,不卖单纯工具,而是直接承接 510(k)、De Novo、PMA、IND、NDA、BLA 等 FDA 申报流程,卖的是更快、更便宜、风险更低的审批交付结果。
为什么值得关注: - 这是“AI + 专家服务”最值得借鉴的一种形态:AI 不单卖 seat,而是嵌进高价值专业服务,按里程碑卖结果。 - FDA 申报本来就长周期、重文档、强责任,天然适合把人工咨询公司升级成 AI-native 交付公司。 - 对创业者的启发是:如果你面对的是极高客单价的专业流程,AI 的最佳商业模式可能不是 SaaS,而是 software-enabled service / outcome-as-a-service。
类比参考:“FDA 申报版 AI-native 咨询公司”
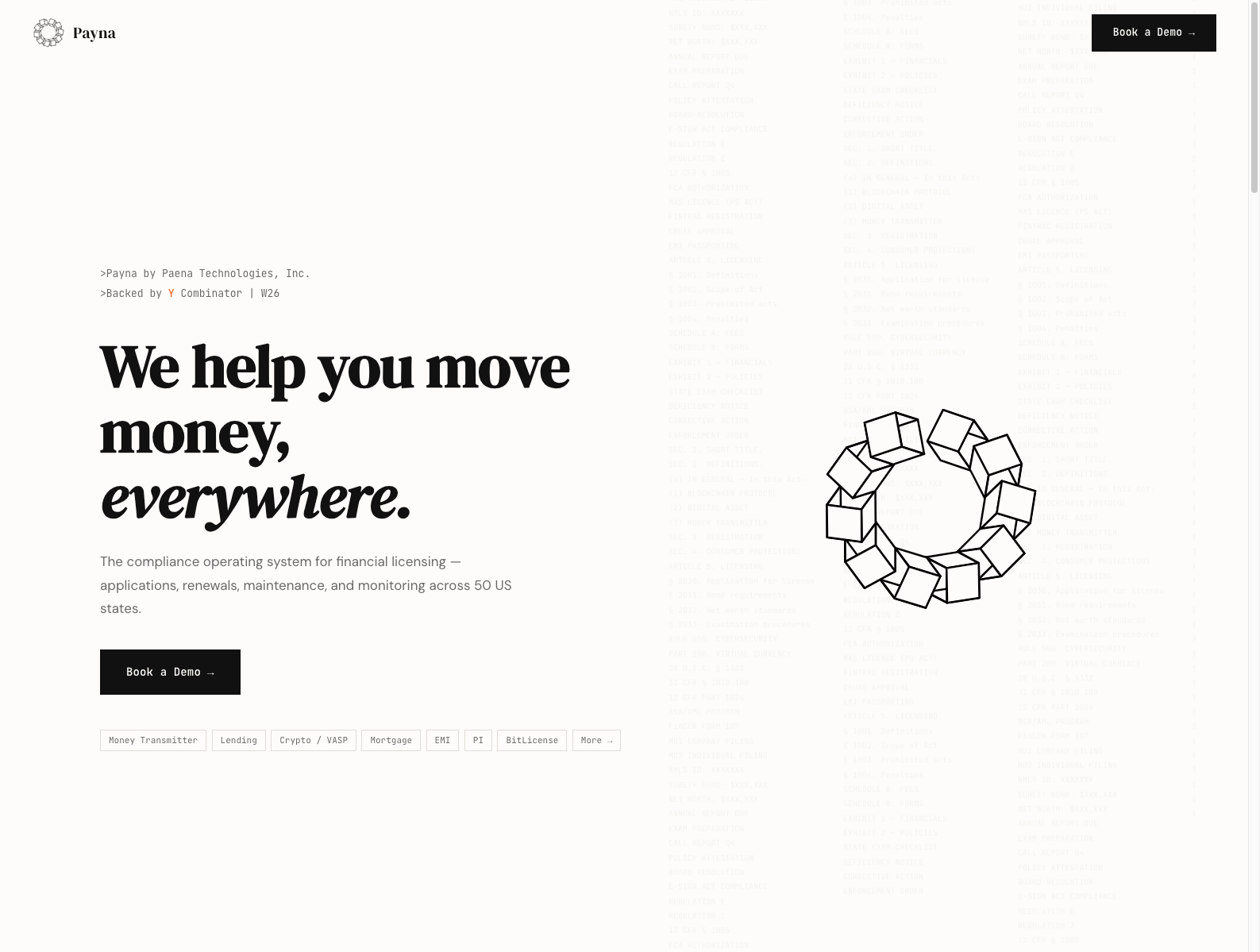
融资信息:获 Y Combinator 支持;官网与 YC 页面未披露独立融资金额。
做什么的:Payna 把金融持牌、续牌、维护、州监管变化追踪、考试准备、材料预填这些极度碎片化的工作做成一套 compliance operating system,覆盖美国 50 个州及多个金融细分牌照场景。
为什么值得关注: - 这类业务过去往往靠外部律所、顾问和 Excel 驱动,Payna 的机会在于把原本“人肉项目管理”的合规工作流产品化。 - 它最有价值的不是自动生成文书,而是把法规变化、开始时间、依赖关系、通过概率都组织成可执行系统。 - 对创业者的启发是:AI 在高监管行业真正能卖出去的,不是“懂法规”,而是 帮客户持续保持可运营状态。
类比参考:“跨州金融持牌版 Vanta + workflow OS”
今天最值得创业者注意的,不是又多了一个通用 Agent,而是一批 AI 创业公司开始直接重做老行业的软件骨架:有的把合规层塞进模型与用户之间,有的把护理机构、医院、酒类零售、浏览器自动化、语音外呼这些老工作流整包重写。一个清晰信号是,AI 产品的下一波机会正在从“外挂式 copilot”转向“AI 原生操作系统 + 行业专用基础设施”。谁能把旧系统里最重、最慢、最贵的一段流程吃下来,谁就更容易拿到真正持续的预算。
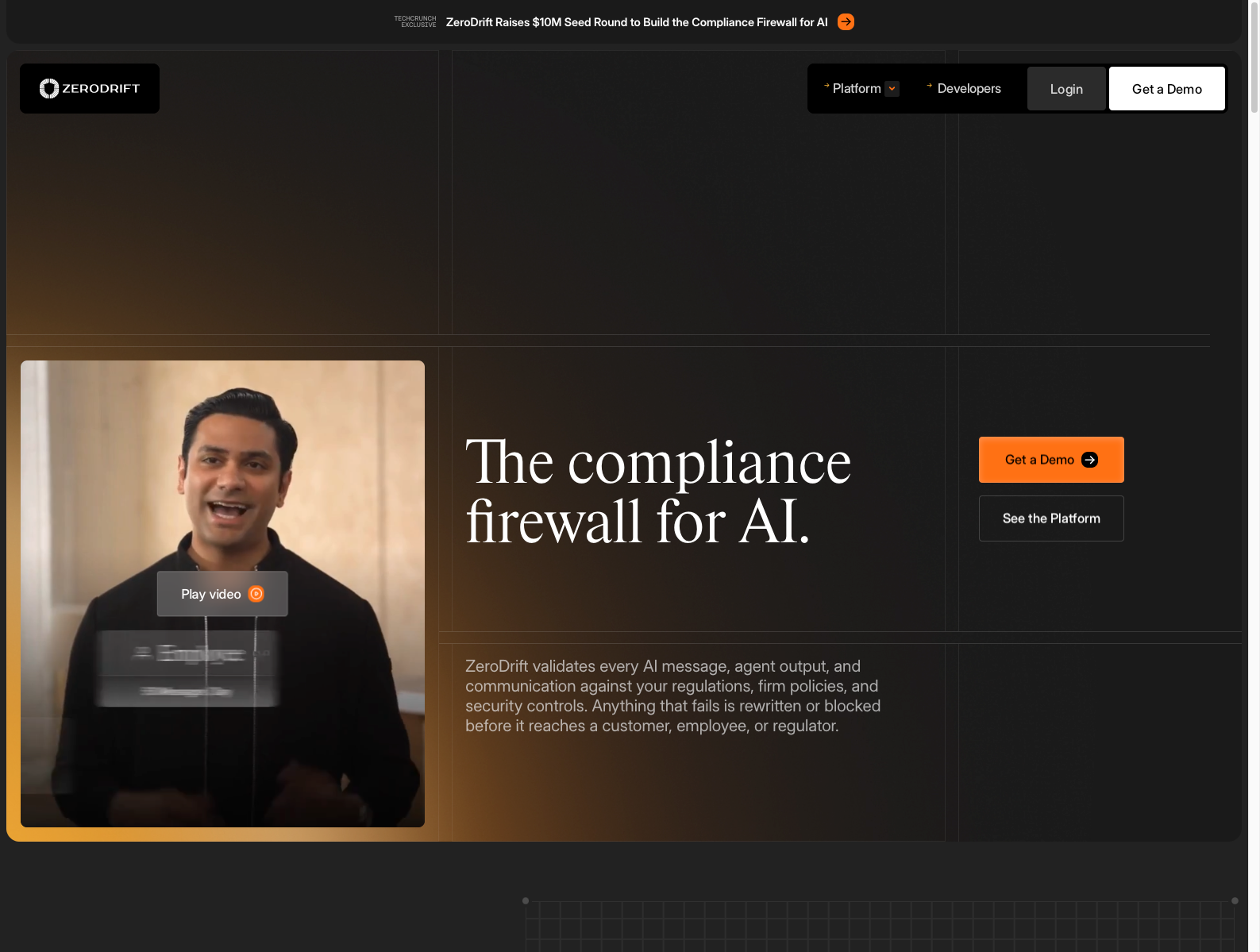
🔗 链接:官网 | TechCrunch 融资报道
融资信息:Seed 轮 1000 万美元;投资方包括 a16z Speedrun、Reign Ventures、Pitchdrive、U&I Ventures 等。
做什么的:在模型和终端用户之间加一层“AI 合规防火墙”,先用确定性规则识别 SOC 2、GDPR 等合规风险,再用 LLM 重写成合规输出。
为什么值得关注: - 它不是做“更安全的聊天机器人”,而是在做 模型外部的治理执行层。 - 这类产品的价值不在回答更聪明,而在 更低延迟、更高可控性、更强审计性。 - 对创业者的启发是:高监管行业里,AI 的预算往往不先给生成层,而是先给 风控、拦截、审计和责任归属层。
类比参考:“Cloudflare / Palo Alto 的 AI 输出合规版”
融资信息:YC Spring 2026 批次,融资金额未披露。YC 页面显示其已与 6 家护理机构、200+ 员工合作试跑整套业务运营。
做什么的:面向 home care、aged care、disability services 机构的 AI 原生操作系统,覆盖 rostering、CRM、notes、messaging、timesheets、invoicing、compliance,并用 AI agents 接管文书和后台 admin。
为什么值得关注: - 它不是在旧护理软件上加一个 copilot,而是直接把 “业务系统 + AI 执行层” 一起重做。 - 护理与照护行业长期被高频低效 admin 工作拖住,TakeCareOS 切的是最容易形成 ROI 的部分。 - 对创业者的启发是:很多垂直行业真正缺的不是一个 AI 助手,而是一套 默认把 AI 当员工来设计的软件底座。
类比参考:“Home care 版 ServiceTitan / AI-native ERP”
融资信息:YC Spring 2026 批次,融资金额未披露。YC Launch 页面披露,早期诊所场景中已看到 约 3 倍 admin productivity improvement 与 37% revenue recovery。
做什么的:把医院/诊所分散在 EHR、影像、实验室、排班、计费等系统中的数据重新串起来,做成可搜索、可分析、可触发运营动作的 healthcare autonomous OS。
为什么值得关注: - 医疗 AI 里最难的一步常常不是模型,而是 把碎片化数据拼成可执行上下文。 - Eos AI 不是单点做 scribe 或病历总结,而是先做 数据协调层 + 运营动作层。 - 对创业者的启发是:如果一个行业数据极碎,先拿下“统一上下文”这一层,后面的 agent、推荐、自动化才有复利。
类比参考:“Palantir / Snowflake 的医院运营 Agent 版”
融资信息:YC Winter 2026 批次,融资金额未披露;YC 页面显示产品 已进入 beta 并开始上线真实用户。
做什么的:做“口袋里的 AI 家庭医生”,连接病历与 wearable 数据,持续监测用户健康变化,并把传统一年一次的被动体检改成持续式、主动式初级医疗。
为什么值得关注: - 它的切法不是“在线问诊聊天”,而是试图重做 primary care 的服务频率与交互范式。 - 医疗产品里,连续监测 + 风险早筛,比一次性问答更容易建立长期使用场景。 - 对创业者的启发是:AI 最有机会重做的,不只是效率,而是把原本低频的服务改成 持续关系型产品。
类比参考:“One Medical + wearable intelligence 的 AI 版”
🔗 链接:官网 | Crunchbase News | PR Newswire
融资信息:Series A 2000 万美元;由 VMG Partners 领投,First Round Capital、Lerer Hippeau、Toba Capital 跟投。公司披露其 annual run rate gross payment volume 已超过 10 亿美元。
做什么的:为酒类零售店提供 AI-native POS、back office、inventory、invoice reconciliation、pricing intelligence 与 e-commerce 一体化系统。
为什么值得关注: - 酒类零售是典型“看起来小众、其实极复杂”的行业,SKU 多、分销链长、合规和进销存都很重。 - Scotch 的产品策略不是做通用零售 SaaS,而是把一个被忽视行业的核心工作流 从底层完全重构。 - 对创业者的启发是:最好的垂直 SaaS 机会,往往藏在 被主流软件长期服务不好的细分行业。
类比参考:“Drizly 之后的 liquor retail OS / 酒类零售版 Toast”
🔗 链接:官网 | Fortune 报道 | BetaKit 报道
融资信息:累计宣布 6000 万美元 Series A 相关融资,包括 2500 万美元 Series A 与 3500 万美元 Series A extension;公开报道显示由 Framework Ventures 领投,并获 SV Angel、Ted Xiao 等支持。
做什么的:做 physical AI 的数据与部署层,采集第一视角真实任务视频、做人类动作理解与评估,把机器人从实验室 demo 推向真实场景部署。
为什么值得关注: - Physical AI 最缺的不是再多一个模型,而是 足够真实、可训练、可评估、可部署的数据闭环。 - Mecka 的定位不是造机器人,而是做机器人生态里的 integrator + data engine。 - 对创业者的启发是:具身智能的高价值层,未必在整机,更可能在 数据、评估、集成与商业交付中间层。
类比参考:“Scale AI / Anduril 在 Physical AI 数据层的结合体”
🔗 链接:官网 | TechCrunch 报道 | Tech.eu 报道
融资信息:Pre-seed 300 万美元;由 4DX Ventures 领投,Enza Capital、Dorm Room Fund、Mojo Ventures、Stanford GSB 26 Fund 等参投。
做什么的:面向中东和非洲市场做方言友好的 voice AI 基础设施,覆盖法语、阿拉伯语、英语的本地口音与低延迟语音交互,并同步推出 API / SDK。
为什么值得关注: - 它没有沿用通用 voice stack,而是自己做小模型和 orchestration,解决 emerging markets 下的 高延迟、口音复杂、基础设施不均衡 问题。 - 这类公司抓住的是“被全球主流模型忽略的市场空白”,不是正面卷美国标准场景。 - 对创业者的启发是:全球化 AI 创业不一定靠更大模型,很多时候靠 更本地化的数据、更小的模型、更懂区域约束的工程。
类比参考:“Vapi / ElevenLabs 的新兴市场本地化版本”
🔗 链接:官网 | YC Launch | Hacker News
融资信息:YC S22 公司,本次为新产品/新能力曝光,融资金额本轮未披露。
做什么的:让用户用自然语言描述需求,由 AI 生成 production-ready 的 Playwright 浏览器自动化代码、部署到平台,并在网站结构变化后自动修复与重部署。
为什么值得关注: - 它不是普通的“AI 帮你录制 RPA”,而是把 生成代码、运行基础设施、观测日志、故障修复 做成一体化闭环。 - 对很多企业来说,重复执行的浏览器任务需要的是代码级稳定性,而不是一次性演示型 agent。 - 对创业者的启发是:AI 最有价值的形态之一,不是完全替代代码,而是把 代码生产、维护、诊断 这几个最贵环节压缩掉。
类比参考:“Retool Workflows + Playwright Cloud + self-healing agent”
今天最值得创业者注意的,不是又多了一个 AI 助手,而是垂直 AI 产品开始同时向两端延伸:一端往更深的系统执行层走,直接接管诊所、病理、物业、临床试验等高摩擦流程;另一端往更轻的端侧基础设施走,用本地推理把成本、安全和响应速度重新做一遍。对创业者来说,这意味着新一轮机会不在通用聊天层,而在 “结果交付 + 工作流嵌入 + 成本结构重写” 的三者交叉点。
注:受当前执行环境的浏览器外部导航策略限制,文内截图改为基于公开产品页面信息生成的本地卡片图,用于本地预览与后续分发占位;产品链接均指向官网或融资来源页。
🔗 链接:融资报道
融资信息:天使+轮,数千万元人民币;投资方为峰瑞资本。公开信息显示,此前公司亦获过早期天使轮支持,本次属于轮次更新。
做什么的:聚焦端侧 AI 推理引擎与本地智能平台,试图把大模型能力从云端搬到个人设备和边缘终端。
为什么值得关注: - 这不是又一家“做模型”的公司,而是在补 Agent 时代的端侧算力基础设施。 - 如果端侧推理真能把成本再压一个数量级,很多原本只能云上跑的 AI 场景,会第一次具备大规模落地条件。 - 对创业者的启发是:当大家卷应用层时,更低成本、更安全、更可控的部署层 反而可能更容易沉淀壁垒。
类比参考:“本地优先 AI runtime / 端侧推理引擎版的基础设施公司”
融资信息:YC Spring 2026 批次,融资金额未披露。
做什么的:用一组 AI agents 接管澳大利亚 GP 诊所的行政与运营流程,覆盖 clinic admin 和 operations。
为什么值得关注: - 医疗 AI 最难的往往不是诊断,而是那些高频、重复、碎片化的后台工作。 - Care GP 的价值主张很清楚:不是给前台一个聊天助手,而是直接替诊所吞掉行政负担。 - 对创业者的启发是:在强监管行业里,先切运营成本,再切临床决策,通常更容易起量。
类比参考:“医疗诊所版的 AI back office team”
融资信息:YC Spring 2026 批次,融资金额未披露。
做什么的:给机器人公司做多模态训练数据的采集、切分、标注和可视化,让机器人模型先把“数据层”打磨好。
为什么值得关注: - 机器人领域最缺的往往不是模型想法,而是持续、可复用、可解释的数据流水线。 - Shotwell 把“Better data. Better robots.”做成了清晰产品叙事,本质是在卖机器人训练效率。 - 对创业者的启发是:Physical AI 的高价值机会,很多不在整机,而在 上游数据基础设施。
类比参考:“Scale AI 的机器人数据版”
融资信息:YC Spring 2026 批次,融资金额未披露。
做什么的:面向病理医生的实时 AI scribe,医生边看切片边口述,系统同步生成结构化报告并写入正确字段。
为什么值得关注: - 它不是泛化的“医疗语音转写”,而是直接卡在病理报告这个高价值、强结构化、强专业术语的岗位流上。 - 真正的产品壁垒来自 字段级结构化、既有系统兼容、医生个体风格学习。 - 对创业者的启发是:垂直 AI 不一定要颠覆工作流,很多时候 “挂在原系统之上” 反而更容易成交。
类比参考:“病理科版 Nuance + AI copilot”
融资信息:YC Spring 2026 批次,融资金额未披露。
做什么的:做 Agent Experience 平台,帮助产品团队理解 AI agent 如何发现、理解、尝试和卡住在你的产品里。
为什么值得关注: - 过去大家做 UX,现在开始有人系统性做 AX(Agent Experience)。 - 当 agent 成为新用户后,传统埋点并不能告诉你 agent 为什么失败,而 Scope 正在补这一层观测与优化工具。 - 对创业者的启发是:如果你的产品未来要被 agent 调用,对 agent 友好 会像移动端适配一样成为基础能力。
类比参考:“PostHog / FullStory 的 Agent 版”
融资信息:YC Spring 2026 批次,融资金额未披露。
做什么的:用合规型 agent automation 打通临床试验全流程,从 protocol design 一直到 FDA submission。
为什么值得关注: - 临床试验一直是最典型的“流程慢、文档重、审计强”领域,非常适合 AI 去压缩周期。 - Astraea 的价值不只在自动化,而在 标准感知、可追踪、可审计 的执行层设计。 - 对创业者的启发是:在高监管赛道卖 AI,最好卖的不是“聪明”,而是 更快且仍然合规。
类比参考:“Veeva 工作流的 agent 化版本”
融资信息:YC Spring 2026 批次,融资金额未披露。
做什么的:给公司里的 AI agents 提供共享记忆、共享工具、共享工作流和可复用产物,让 AI 工作不再散落在个人聊天线程里。
为什么值得关注: - 它切中的是真实团队痛点:现在很多公司不是没有 agent,而是 agent 的产出无法沉淀和复用。 - “One MCP for memory, tools, workflows, and agent work” 这个定位很强,说明 agent 协作层开始从 hacky 脚本走向正式产品。 - 对创业者的启发是:当多 agent 成为常态,共享上下文和组织记忆 会变成新的协作基础设施。
类比参考:“Notion + MCP + agent workspace 的混合体”
融资信息:YC Spring 2026 批次,融资金额未披露。
做什么的:通过真实受访者构建 1:1 AI customer clones,用于测试定价、创意、问卷、产品路径和市场扩张假设。
为什么值得关注: - 市场研究正在从“找样本、做访谈、等报告”转向“先用模拟人群高频试错”。 - Auxos 不是泛用户画像工具,而是在卖 决策前模拟,这对增长、品牌、产品团队都很有吸引力。 - 对创业者的启发是:只要你能把“试错成本”压低一个数量级,就可能改写一个老行业的工作方式。
类比参考:“Qualtrics / 用户研究公司的 AI 模拟版”
融资信息:YC Spring 2026 批次,融资金额未披露。
做什么的:为物业管理公司自动处理租客报修、供应商协调和维修跟进,减少物业团队的人力扩张需求。
为什么值得关注: - 物业是标准的高沟通、高催办、高碎片流程行业,非常适合 AI 接管“推进和协调”层。 - 这类产品的价值不在炫技,而在于把一个看似低科技的行业做成 高 ROI 的 agent 场景。 - 对创业者的启发是:很多最值得做的 AI 产品,不在热门赛道,而在那些没人愿意做、但客户每天都在为之付钱的流程里。
类比参考:“物业维修调度员的 AI 版”
 Jowe_Lin
Jowe_Lin