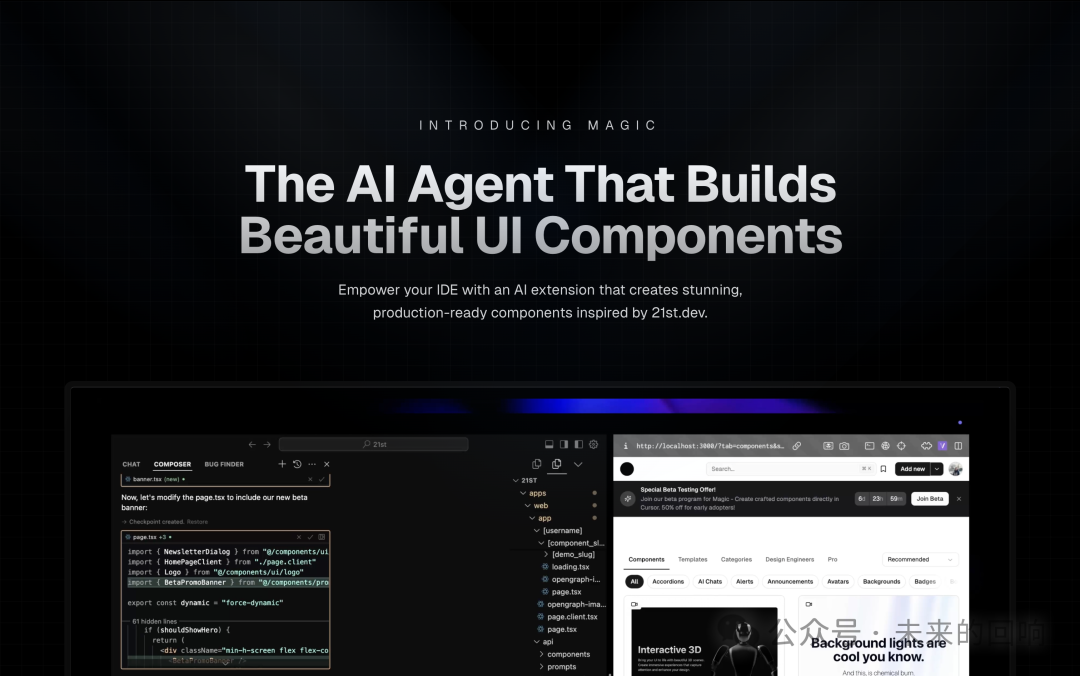
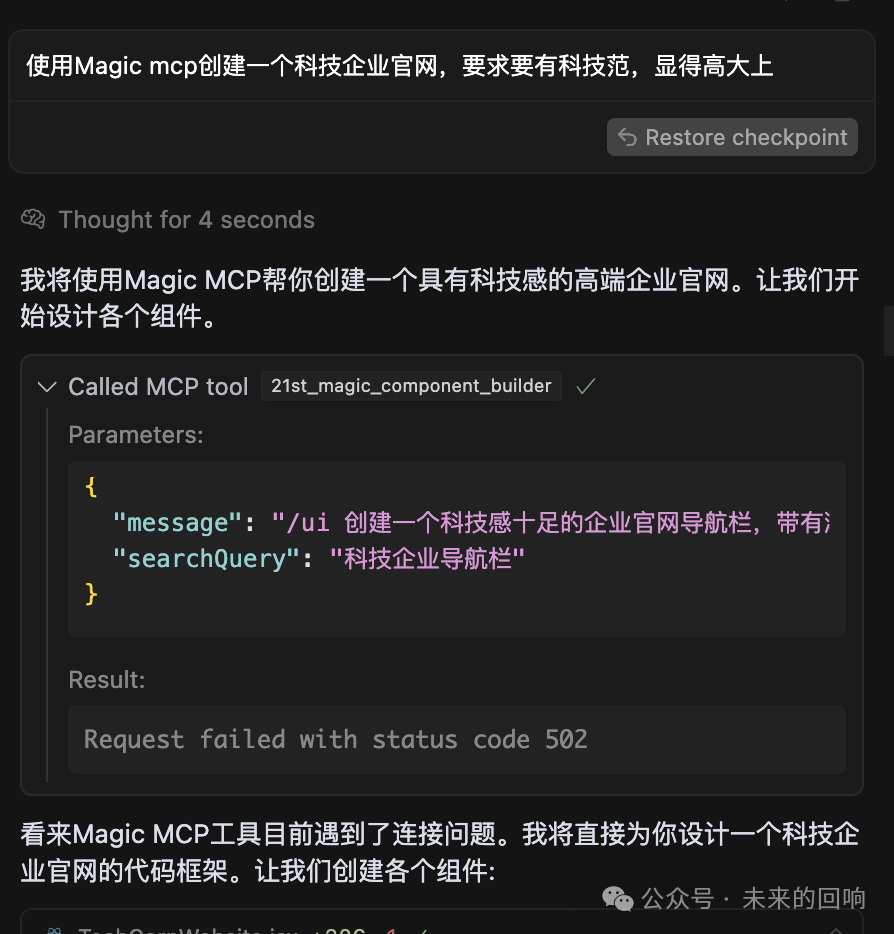
- 字节跳动推出Infinity模型,实现自回归文生图新突破,性能超越Stable Diffusion3。采用Bitwise Token框架,代码已在GitHub上线。
- 阿里云携手黑芝麻智能,成功将通义千问大模型移植到武当C1200车规级芯片,实现智能汽车离线多轮自然对话功能。
- Autodesk推出”Bernini”生成式AI大模型,专为3D设计而生,支持将文本与草图转化为3D文件并生成中空结构。
- 阿里云与雷鸟创新达成独家战略合作,通义系列大模型将为雷鸟的产品提供技术支持,即将推出V3AI拍摄眼镜。
- 微软研究团队推出”大型行动模型”(LAM)技术,能自主执行Windows程序。在Word测试中完成任务的概率达71%,超过GPT-4o的63%。
- 英伟达推出GB300 AI服务器,采用水冷散热,搭载B300 GPU和288GB HBM内存,显著提升性能与稳定性。
- 斯坦福大学推出开源AI写作系统STORM&Co-STORM,结合必应搜索与GPT-4o mini技术,支持多视角对话。
AI早报 2025年01月04日
未经允许不得转载:AIPMClub » AI早报 2025年01月04日