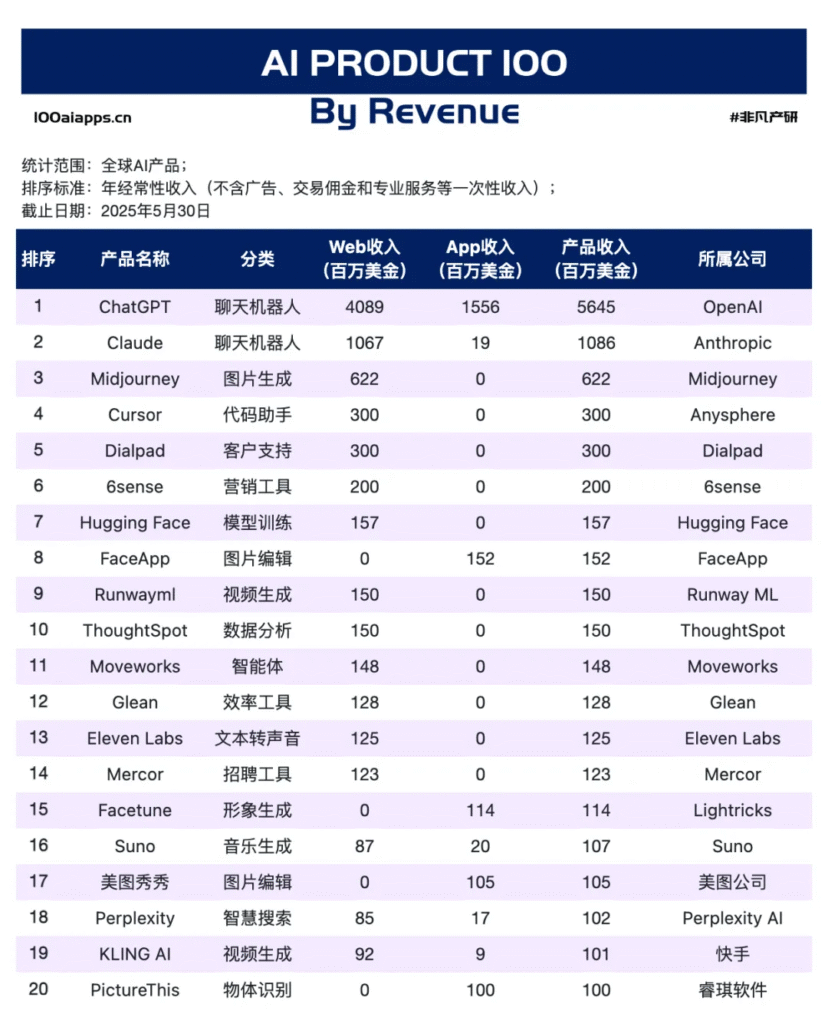
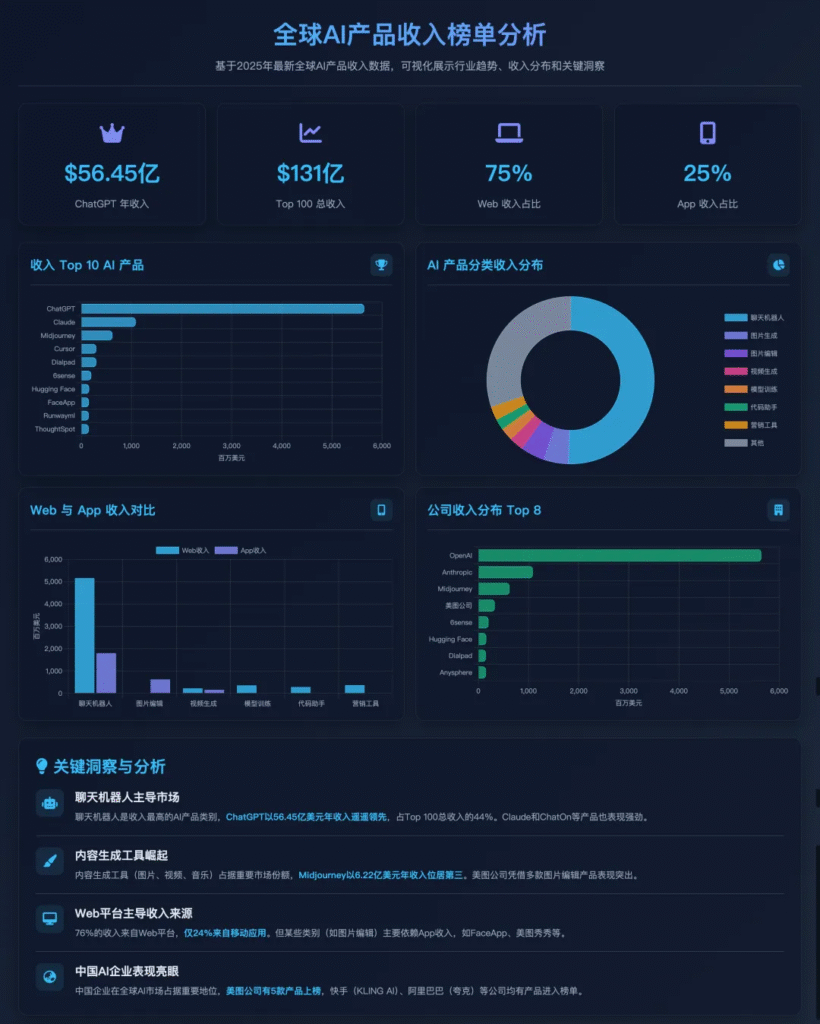
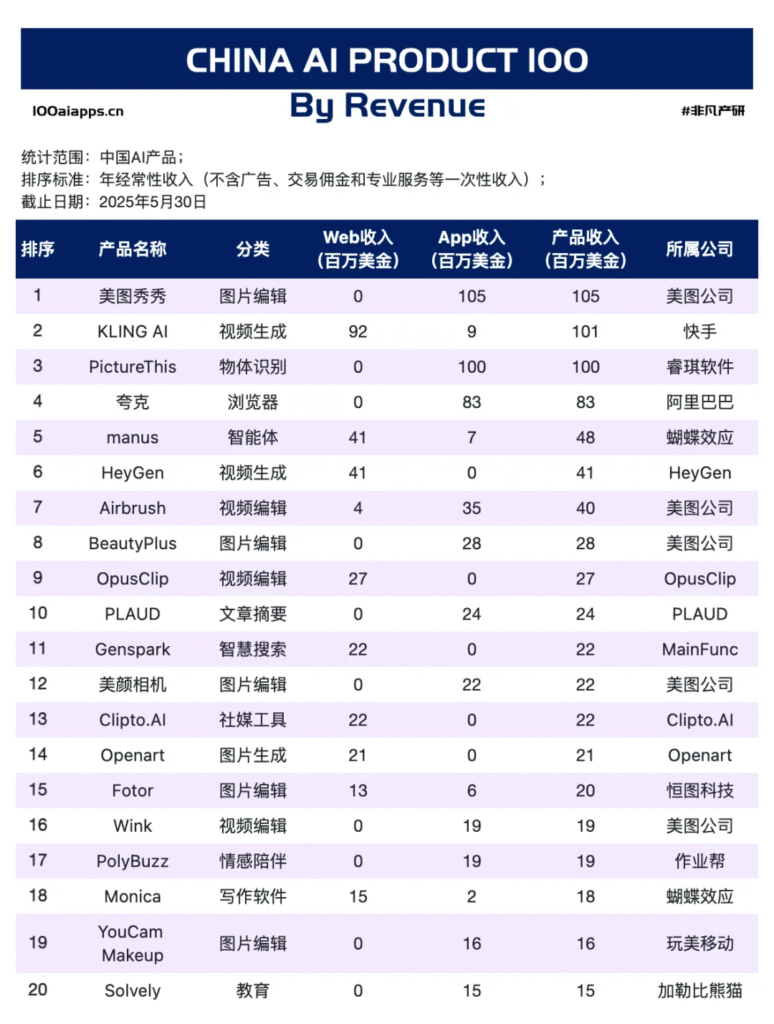
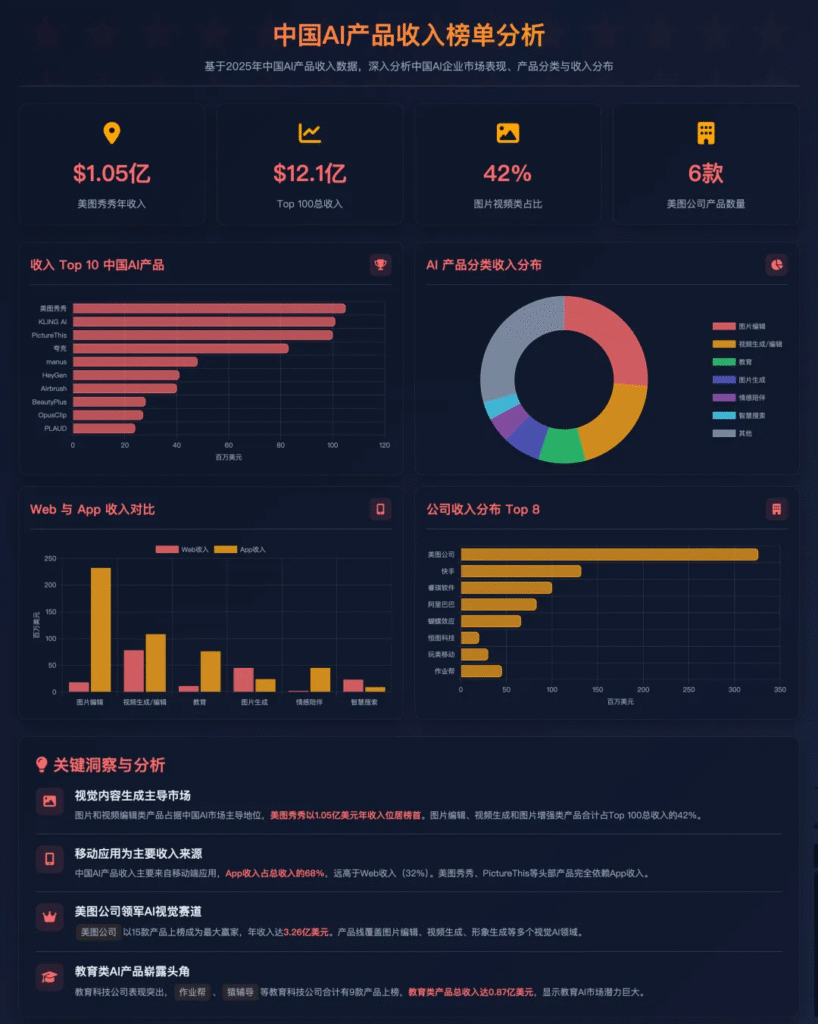
就在今天,豆包APP发布全新更新,实时通话功能迎来全新的交互体验,语音更加拟人化,更加自然,已经完全贴近于人的情感语音。
几个小时后DeepSeek-R1发布,直接对标OpenAI o1,实力直接拉满,DeepSeek-v3已经受到广大用户的狂热追捧。
几分钟前,月之暗面也发布全新的k1.5 新模型,直接做到满血版的OpenAI o1水平。一、7000万日活的超级APP:豆包
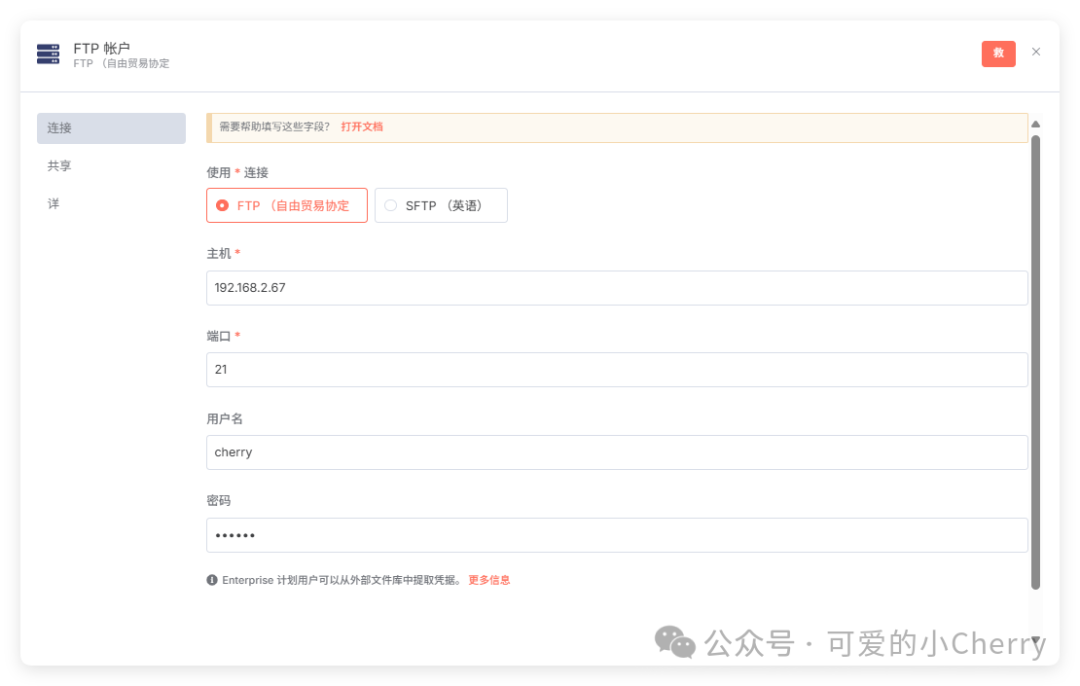
豆包 APP 宣布全新端到端实时语音通话功能正式上线,直接全量上线。
豆包很像人,会说悄悄话,消除了人机感。它中文能力强,无论是和海外的ChatGPT还是国产同类应用相比,都遥遥领先。豆包还很懂聊天,能听懂用户深层含义,回复既有趣又有用,还能联网查询。
豆包实时语音大模型:https://team.doubao.com/realtime_voice
豆包大模型团队从拟人度、有用性、情商、通话稳定性、对话流畅度等多方面对比考评了豆包实时语音大模型和GPT – 4o。前者整体满意度评分为4.36,GPT – 4o为3.18,满分5分。其中,50%的测试者给豆包实时语音大模型打了满分。

二、AI界的拼多多—DeepSeek:从默默无闻到一鸣惊人DeepSeek是一家创新型科技公司,专注于开发先进的大语言模型(LLM)和相关技术。其致力于通过前沿的人工智能研究和创新,推动语言模型在各个领域的应用和发展,为用户提供高效、智能的解决方案。
2024年1月5日,DeepSeek LLM大模型率先登场,携670亿参数开启新征程。20天后的1月25日,DeepSeek-Coder系列代码语言模型紧随其后,为编程领域注入新活力。进入2月,2月5日,DeepSeekMath耀世而出,在数学推理赛道上,其性能与Gemini-Ultra和GPT-4齐头并进,令人瞩目。3月11日,视觉与语言的桥梁——DeepSeek-VL模型搭建完成,它能精准洞察高分辨率图像的多模态奥秘。时光流转至5月7日,第二代开源Mixture-of-Experts(MoE)模型DeepSeek-V2华丽亮相,以更强性能和更低训练成本,为模型发展树立新标杆。6月17日,DeepSeek-Coder-V2升级归来,支持编程语言从86种飞跃至338种,同时在上下文长度和任务表现上一骑绝尘,超越诸多对手。9月5日,DeepSeek V2.5如约而至,巧妙融合DeepSeek Coder V2和DeepSeek V2 Chat两大模型,实现功能的华丽转身与全面升级。岁末将至,12月13日,专家混合视觉语言模型DeepSeek-VL2发布,向着高级多模态理解的高峰攀登。12月26日,DeepSeek-V3大模型震撼发布并开源,以557万美元的超低训练成本,在中外AI圈掀起巨浪,与OpenAI GPT-4 7800万美元的高昂成本形成强烈反差。
DeepSeek-V3模型是去年12月份正式上线。参数:自研 MoE 模型,671B 参数,激活 37B,14.8T token 预训练。DeepSeek-V3 多项评测成绩超越了 Qwen2.5-72B 和 Llama-3.1-405B 等开源模型,在性能上和 GPT-4o 以及 Claude-3.5-Sonnet 比肩。技术细节:https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf模型 API 服务定价为每百万输入 tokens 0.5 元(缓存命中)/ 2 元(缓存未命中),每百万输出 tokens 8 元。到2025 年 2 月 8 日,DeepSeek-V3 的 API 服务价格是每百万输入 tokens 0.1 元(缓存命中)/ 1 元(缓存未命中),每百万输出 tokens 2 元。

Deepseek于今日发布 DeepSeek-R1,性能比肩OpenAI o1 正式版!!!DeepSeek-R1在训练后期广泛采用了强化学习技术,即便在标注数据极为有限的情况下,也能显著增强模型的推理能力。在数学解题、代码生成以及自然语言推理等众多任务领域,其表现与OpenAI的o1正式版相当,达到了顶尖水平。技术细节:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
在开源DeepSeek-R1-Zero和DeepSeek-R1两个660B模型的同时,DeepSeek团队通过DeepSeek-R1的输出,蒸馏了6个小模型并开源给社区。小模型在性能和效率上都有显著提升,为社区提供了更多高效的选择。
DeepSeek-R1 API 服务定价为每百万输入 tokens 1 元(缓存命中)/ 4 元(缓存未命中),每百万输出 tokens 16 元。现在deepseek客户端就可以体验全新的R1m模型。
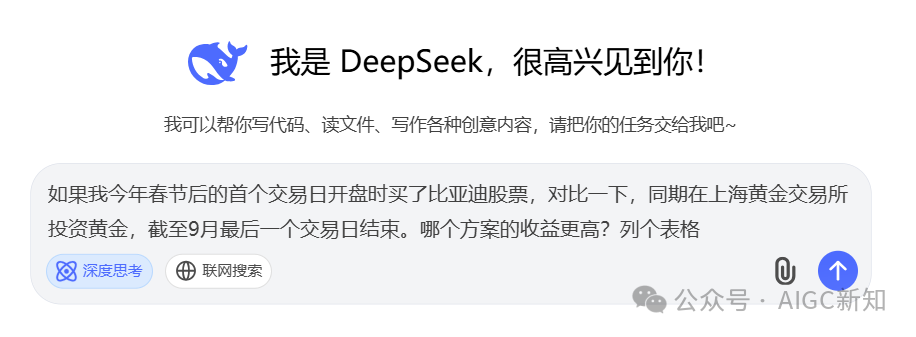
在执行我们给他的一个示例,deepseek会展示思考的步骤,并且思考速度很快。

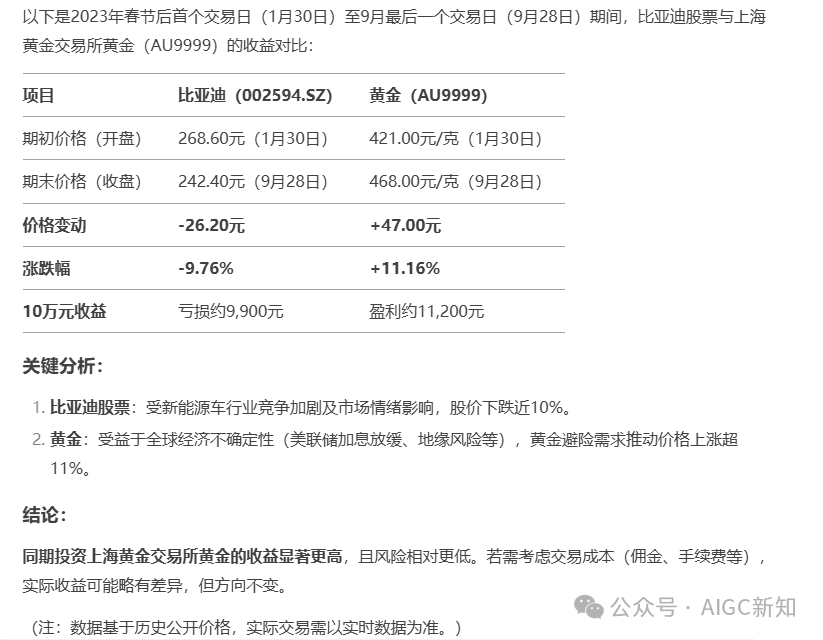
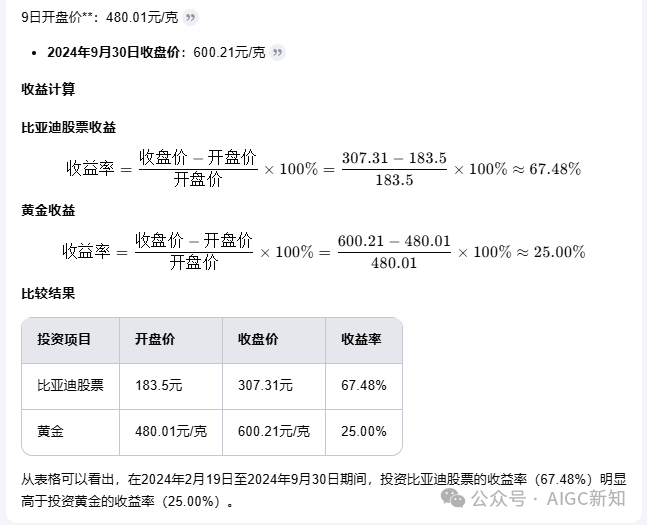
相较于kimi,deepseek的推理能力更加强一点,不会有那种刻板的去搜索、分析然后进行生成的过程,并且在某些任务处理过程中无法保证是否出错。
三、全新的k1.5多模态思考模型在官方展示的一张kimi K思考模型路线图里,经过前两轮k0-math、k1模型的迭代更新,k1.5系列多模态思考模型的发展处于第三阶段,在2025年将完全覆盖更多的模态,甚至全模态的思考模型。kimi数学版 | k0-math用公式勾勒了一个新的数学世界
去年11月份的k0-math,在ZHONGKAO、GAOKAO、KAOYAN以及包含入门级别竞赛题的 MATH 等数学基准测试中,k0-math 就已经超过了 o1-mini 和 o1-preview,位居榜首。在实际测试数学解题能力过程中,表现特别优异。Kimi 发布视觉思考模型 k1,并且悄悄上线了两大语音通话场景能力
视觉思考模型k1,基于强化学习技术打造,原生支持端到端图像理解和思维链技术,不仅仅支持数学能力,还扩展到数学之外的更多基础科学领域。初代k1模型在数学、物理、化学基础科学学科的基准能力测试中,表现超过了 OpenAI o1、GPT-4o以及 Claude 3.5 Sonnet。
通过端到端图像理解能力,各种几何图形题都不再成为拦路虎。
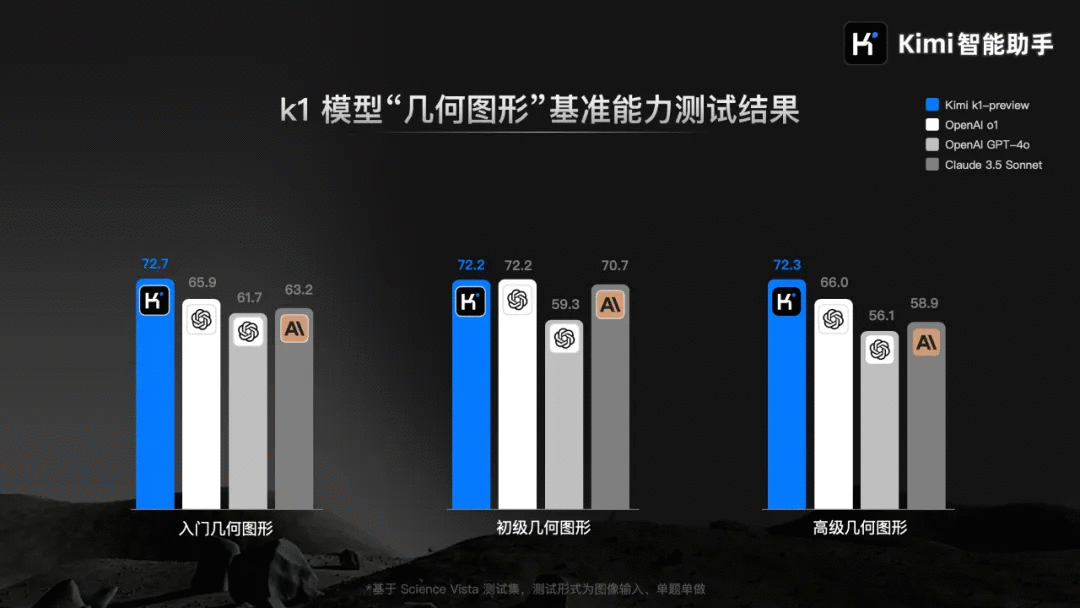
考虑到真实用户在拍照解题时会出现的场景:图片不清晰,油渍、字体模糊,特别是纯手写题目,因人而异,普通大模型基本无法正确识别出题目到底是什么。

本次更新的k1.5 多模态思考模型,实现了 SOTA (state-of-the-art)级别的多模态推理和通用推理能力,能力大幅度提升。
在short-CoT模式下,Kimi k1.5的数学、代码、视觉多模态和通用能力,大幅超越了全球范围内短思考SOTA模型GPT-4o和Claude 3.5 Sonnet的水平。在long-CoT模式下,Kimi k1.5的数学、代码、多模态推理能力,也达到了长思考SOTA模型OpenAI o1正式版的水平。就像开头的那句话:「There is no expedient to which a man will not resort to avoid the real labor of thinking. 人为了不必费力思考,任何取巧方法都不会放过。观看先于言语。」乔舒亚·雷诺兹爵士
在人类的认知过程中,“观看”确实很多时候是先于“言语”的。人并非先天就会人类语言,与生俱来的是视觉、听觉、触觉等,到后天才具备交流、思考的能力。
例如,婴儿在学会说话之前,首先通过视觉来感知世界。他们看到各种物体的形状、颜色,观察人的表情和动作。像当婴儿看到妈妈微笑时,他们会感受到一种愉悦的情绪,这种视觉感知是他们在语言能力形成之前就有的体验。
在很多跨文化交流的场景中,观看也起着关键作用。不同国家的人可能语言不通,但通过观察对方的肢体语言、表情等非言语行为,能够大致理解对方的意图。比如在国际体育赛事中,不同国家的运动员和观众可以通过观察比赛动作、裁判的手势等来进行基本的交流和理解。好了,今天的介绍就到这里了,感谢你的阅读。