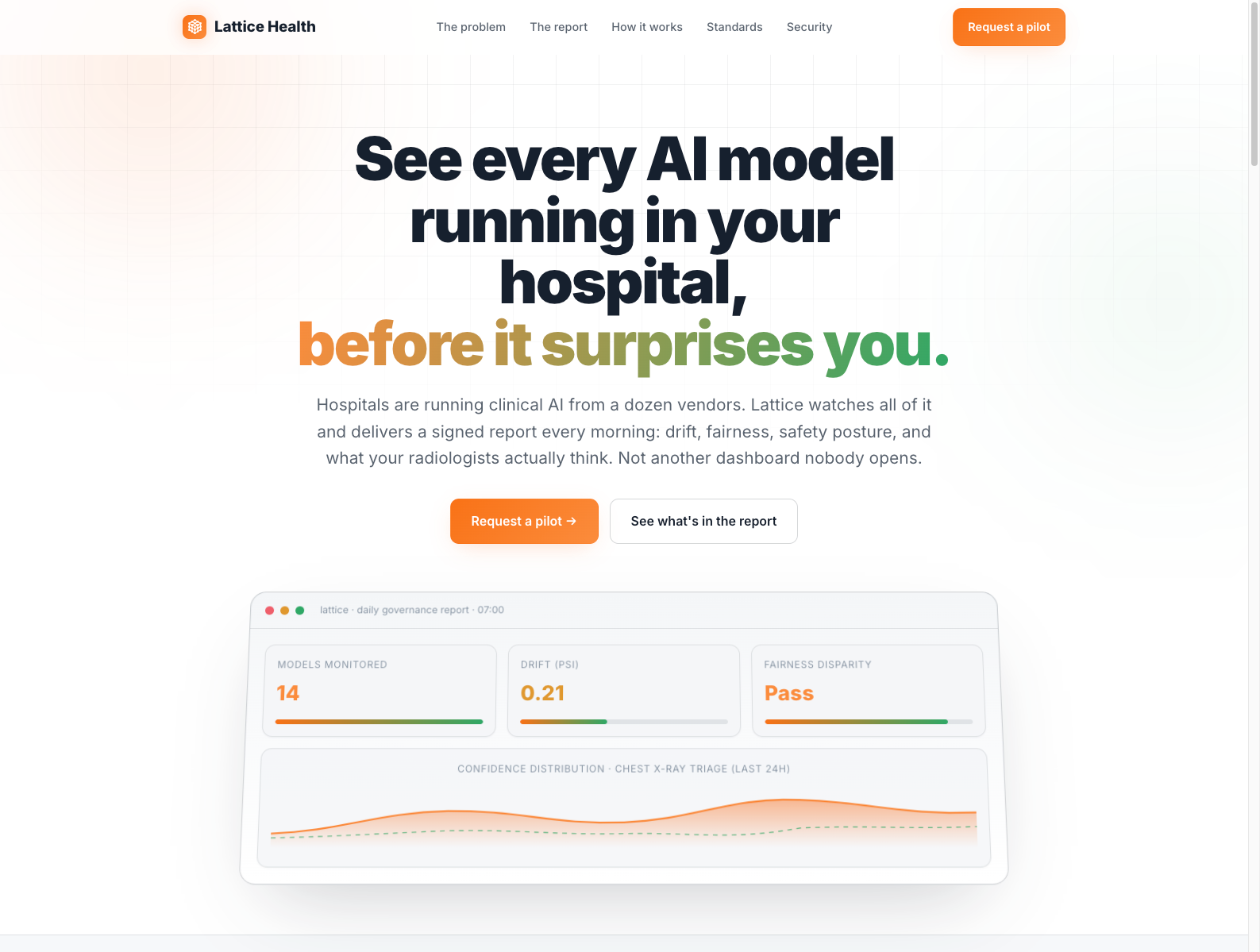
When Nilay Patel of The Verge sat down with Superhuman CEO Shishir Mehrotra, it wasn’t just another tech interview. It was a direct, personal confrontation over AI impersonation, creator rights, and the very soul of digital identity. This wasn’t policy paper rhetoric; this was Patel, a creator whose voice fuels the internet, challenging the architect of Grammarly, a widely-used AI writing assistant, on the ethics of models trained on his own work.
The dialogue cut to the core: powerful AI, intellectual property, and the very definition of creative ownership. Patel, whose distinctive voice and extensive work have undeniably contributed to the vast datasets feeding generative AI, articulated a raw, personal grievance. He felt impersonated, his unique style mimicked by the very technology he meticulously covers. It’s a stark reminder: AI isn’t just data; it’s often derived from human effort.
Attribution vs. Impersonation: The AI’s Ethical Quagmire Deepens
At the heart of their tense exchange lay a fundamental, often blurred distinction: attribution versus outright impersonation. Many AI companies, including those behind ubiquitous tools like Grammarly, view public data as an open buffet—a necessary, undeniable ingredient for technological advancement. Their argument: if content is publicly available, it’s fair game for data ingestion. This stance, however, often sidesteps the profound, almost existential, impact on the creators whose digital fingerprints are being lifted.
Is it merely an algorithmic nod to a style, or is it a direct, unconsented impersonation of an individual? This is precisely where the lines dissolve, and the ethical quagmire deepens. Imagine an AI tool generating text “in the style of Nilay Patel”—his cadence, his specific turns of phrase—without his explicit permission, let alone compensation. This isn’t just summarization with a citation; it’s a digital doppelgänger, potentially diluting a creator’s hard-earned brand, misrepresenting their nuanced views, or even profiting from their unique intellectual capital. The stakes are immense.
The AI Debt: What Do Companies Like Superhuman Owe Creators?
Shishir Mehrotra, as CEO of Superhuman, stands at the epicenter of this challenge. His company’s flagship, Grammarly, is an AI-powered writing assistant used by millions, directly influencing how users communicate. The debate around textual AI ethics isn’t abstract for Superhuman; it’s foundational to their product, their business model, and their future.
The critical question, echoing through this high-stakes exchange and across the entire AI industry, is stark: what do AI companies owe creators? Is a transparent disclosure of training data sufficient? Should an opt-out mechanism be standard? Or does the debt extend to tangible compensation, perhaps a licensing fee, for the use of intellectual property—even if deemed “publicly available”? These aren’t minor details; they define the digital economy’s future.
The answer is elusive, complex. The sheer, unfathomable volume of data involved renders direct negotiation with every single creator practically impossible under existing legal and technical frameworks. Yet, to simply ignore these legitimate concerns is to risk alienating the very creative community—the artists, writers, journalists—who, like digital alchemists, fuel the vast majority of the internet’s value and innovation.
Beyond the Confrontation: AI’s Earthquake for the Entire Tech Ecosystem
This intense dialogue between Patel and Mehrotra transcends a single incident or company. It’s a potent microcosm of a seismic struggle engulfing the entire tech ecosystem. As generative AI advances, its capacity to conjure hyper-realistic text, images, and audio obliterates traditional lines of authenticity and ownership. From unsettling deepfakes to AI-written news articles indistinguishable from human prose, the challenges multiply exponentially.
- Intellectual Property & Copyright: Existing legal frameworks, designed for a pre-AI world, are woefully inadequate. They simply cannot keep pace.
- Authenticity & Trust: How do we discern human ingenuity from algorithmic mimicry? Why does this distinction fundamentally matter for trust in information?
- Fair Compensation: Is it time for a universal basic income for data contributors? How do we fairly compensate creators whose life’s work trains these multi-billion-dollar models?
- Ethical Development: What inherent responsibilities bind developers and product leaders? How do we build AI that intrinsically respects, rather than exploits, human creation?
These aren’t abstract academic musings. They are real-world dilemmas, actively reshaping revenue streams, fueling contentious legal battles, and fundamentally determining the future viability of entire creative industries. The clock is ticking.
Forging a Path Forward: A Mandate for Responsible AI Development
The raw dialogue between Nilay Patel and Shishir Mehrotra serves as a stark, undeniable reminder: AI’s immense power demands an equally immense sense of ethics and profound respect for human endeavor. This isn’t merely about technical innovation. It necessitates thoughtful, proactive policy, robust industry-wide standards, and continuous, candid conversations between AI’s architects and the creators whose work they leverage.
The path forward could involve novel attribution mechanisms, crystal-clear licensing models, or even AI tools architected from day one with creator consent and equitable compensation as non-negotiable tenets. Whatever the ultimate solution, one truth is undeniable: ignoring the legitimate, growing concerns of creators regarding AI impersonation and their fundamental rights is no longer a viable option. The tech industry, spearheaded by companies like Superhuman, bears a profound responsibility. They must define a more equitable, respectful, and sustainable future for artificial intelligence, before the wellspring of human creativity runs dry.