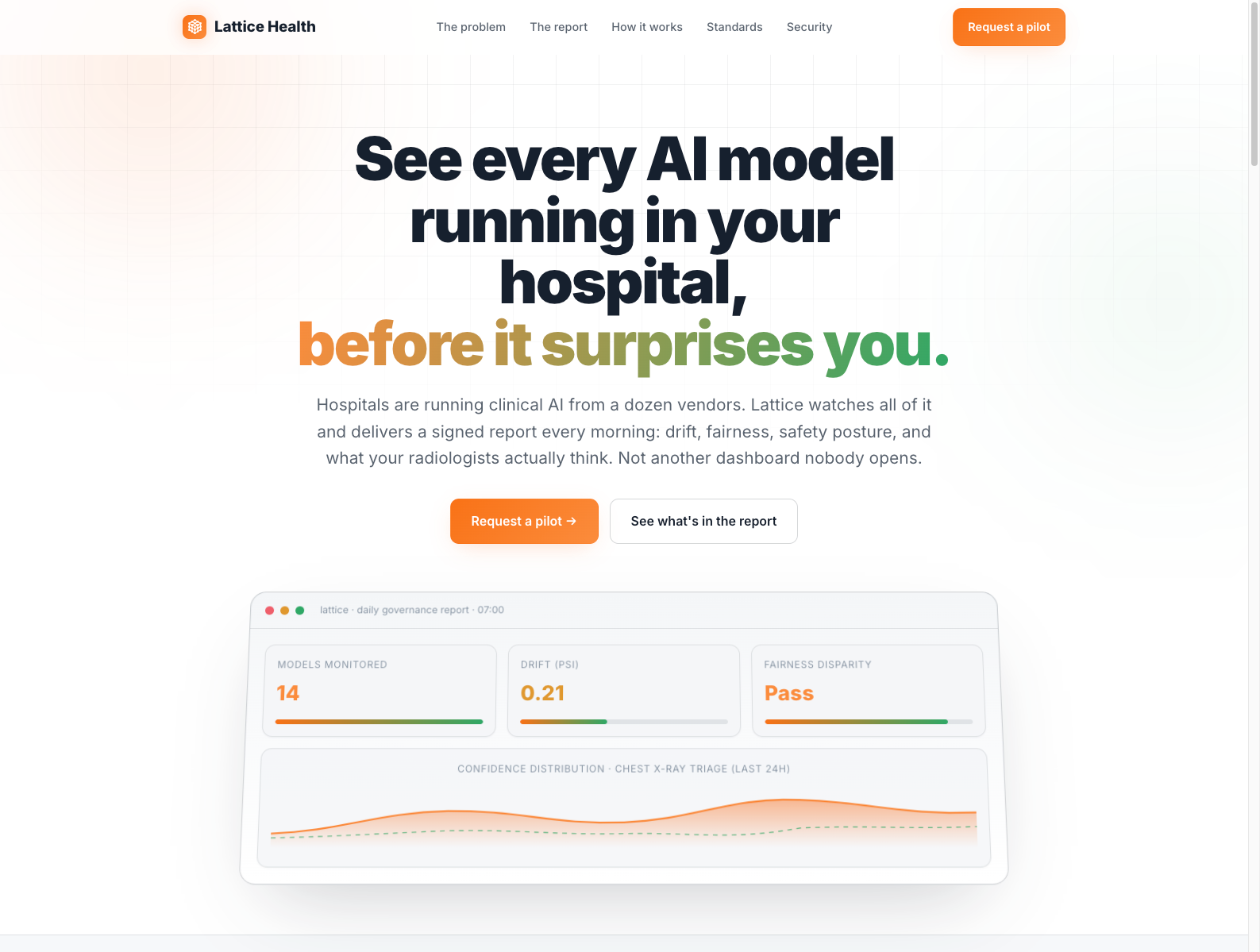
Today, I have compiled a list of 32 Python web scraping projects for everyone.
I’ve gathered these projects because web scraping is a simple and fast way to get started with Python, and it’s also great for beginners to build confidence. All the links point to GitHub, so have fun exploring! O(∩_∩)O~
- WechatSogou [1] – A WeChat public account crawler based on Sogou’s WeChat search. It can be expanded to a Sogou search-based crawler, returning a list where each item is a dictionary of detailed public account information.
- DouBanSpider [2] – A Douban book crawler. It can scrape all books under Douban’s book tags, rank them by rating, and store them in Excel for easy filtering, such as finding highly-rated books with over 1,000 reviewers. Different topics can be saved in separate sheets. It uses User Agent spoofing and random delays to mimic browser behavior and avoid being blocked.
- zhihu_spider [3] – A Zhihu crawler. This project scrapes user information and social network relationships on Zhihu. It uses the Scrapy framework and stores data in MongoDB.
- bilibili-user [4] – A Bilibili user crawler. Total data: 20,119,918. Fields include user ID, nickname, gender, avatar, level, experience points, followers, birthday, address, registration time, signature, and more. It generates a Bilibili user data report after scraping.
- SinaSpider [5] – A Sina Weibo crawler. It mainly scrapes user personal information, posts, followers, and followings. It uses Sina Weibo cookies for login and supports multiple accounts to avoid anti-scraping measures. It primarily uses the Scrapy framework.
- distribute_crawler [6] – A distributed novel download crawler. It uses Scrapy, Redis, MongoDB, and graphite to implement a distributed web crawler. The underlying storage is a MongoDB cluster, distributed via Redis, and the crawler status is displayed using graphite. It mainly targets a novel website.
- CnkiSpider [7] – A CNKI (China National Knowledge Infrastructure) crawler. After setting search conditions, it executes
src/CnkiSpider.pyto scrape data, stored in the/datadirectory. The first line of each data file contains the field names. - LianJiaSpider [8] – A Lianjia crawler. It scrapes historical second-hand housing transaction records in Beijing. It includes all the code from the Lianjia simulated login article.
- scrapy_jingdong [9] – A JD.com crawler based on Scrapy. Data is saved in CSV format.
- QQ-Groups-Spider [10] – A QQ group crawler. It batch scrapes QQ group information, including group name, group number, member count, group owner, group description, etc., and generates XLS(X) / CSV result files.
- wooyun_public [11] – A WooYun crawler. It scrapes WooYun’s public vulnerabilities and knowledge base. All public vulnerabilities are stored in MongoDB, taking up about 2GB. If the entire site, including text and images, is scraped for offline querying, it requires about 10GB of space and 2 hours (10M broadband). The knowledge base takes up about 500MB. Vuln search uses Flask as the web server and Bootstrap for the frontend.
- spider [12] – A hao123 website crawler. Starting from hao123, it scrolls to scrape external links, collects URLs, and records the number of internal and external links on each URL, along with the title. Tested on Windows 7 32-bit, it can collect about 100,000 URLs every 24 hours.
- findtrip [13] – A flight ticket crawler (Qunar and Ctrip). Findtrip is a Scrapy-based flight ticket crawler, currently integrating data from two major ticket websites in China (Qunar + Ctrip).
- 163spider [14] – A NetEase client content crawler based on requests, MySQLdb, and torndb.
- doubanspiders [15] – A collection of Douban crawlers for movies, books, groups, albums, and more.
- QQSpider [16] – A QQ Zone crawler, including logs, posts, personal information, etc. It can scrape 4 million pieces of data per day.
- baidu-music-spider [17] – A Baidu MP3 site crawler, using Redis for resumable scraping.
- tbcrawler [18] – A Taobao and Tmall crawler. It can scrape page information based on search keywords and item IDs, with data stored in MongoDB.
- stockholm [19] – A stock data (Shanghai and Shenzhen) crawler and stock selection strategy testing framework. It scrapes stock data for all stocks in the Shanghai and Shenzhen markets over a selected date range. It supports defining stock selection strategies using expressions and multi-threading. Data is saved in JSON and CSV files.
- BaiduyunSpider [20] – A Baidu Cloud crawler.
- Spider [21] – A social data crawler. It supports Weibo, Zhihu, and Douban.
- proxy pool [22] – A Python crawler proxy IP pool.
- music-163 [23] – A crawler for scraping comments on all songs from NetEase Cloud Music.
- jandan_spider [24] – A crawler for scraping images from Jiandan.
- CnblogsSpider [25] – A Cnblogs list page crawler.
- spider_smooc [26] – A crawler for scraping videos from MOOC.
- CnkiSpider [27] – A CNKI crawler.
- knowsecSpider2 [28] – A Knownsec crawler project.
- aiss-spider [29] – A crawler for scraping images from the Aiss app.
- SinaSpider [30] – A crawler that uses dynamic IPs to bypass Sina’s anti-scraping mechanism for quick content scraping.
- csdn-spider [31] – A crawler for scraping blog articles from CSDN.
- ProxySpider [32] – A crawler for scraping and validating proxy IPs from Xici.
Update:
webspider [33] – This system is a job data crawler primarily using Python 3, Celery, and requests. It implements scheduled tasks, error retries, logging, and automatic cookie changes. It uses ECharts + Bootstrap for frontend pages to display the scraped data.